































Today, customers expect integrations from their SaaS and Services providers. No work gets done in a vacuum, and a strong integration ecosystem improves user experiences, making buying decisions easier.
However, building a reliable pipeline in-house is almost never the best use of engineering hours, especially when customers can and will request hundreds of integrations. This has led to the adoption of solutions that provide pre-built, turnkey integrations that immediately provide a network of connections out-of-the-box.
iPaaS and Reverse ETL are the leading data movement methods employed by businesses today. They were originally introduced to power internal company use cases, such as personalizing marketing emails, sending demo request notifications, or updating a customer’s payment information. Now, both methods can power external data sharing with customers and partners by being embedded into your product or service.
Embedded iPaaS is a disaster waiting to happen
iPaaS excels at delivering quick integrations between a few systems with low complexity. However, once your business’s needs scale, the iPaaS maintenance burden quickly spirals out of control.
With internal use cases, iPaaS’s shortcomings in scalability, data quality, and reliability are burdensome, inefficient, and lead to loss of trust within an organization. For more on what each solution is and how they are differently suited for internal use cases, check out iPaaS vs. Reverse ETL: Choosing the Right Tool for Data Integration.
When working with external customers and partners, Embedded iPaaS is downright dangerous. It is not acceptable to have data discrepancies, long customer support threads, and broken SLAs when dealing with your customers’ data. And the more an Embedded iPaaS implementation scales, the bigger the threat becomes.
Promises to customers require the most robust, observable, low-maintenance, and accurate integration tools. That is exactly where Reverse ETL and Census Embedded shine.
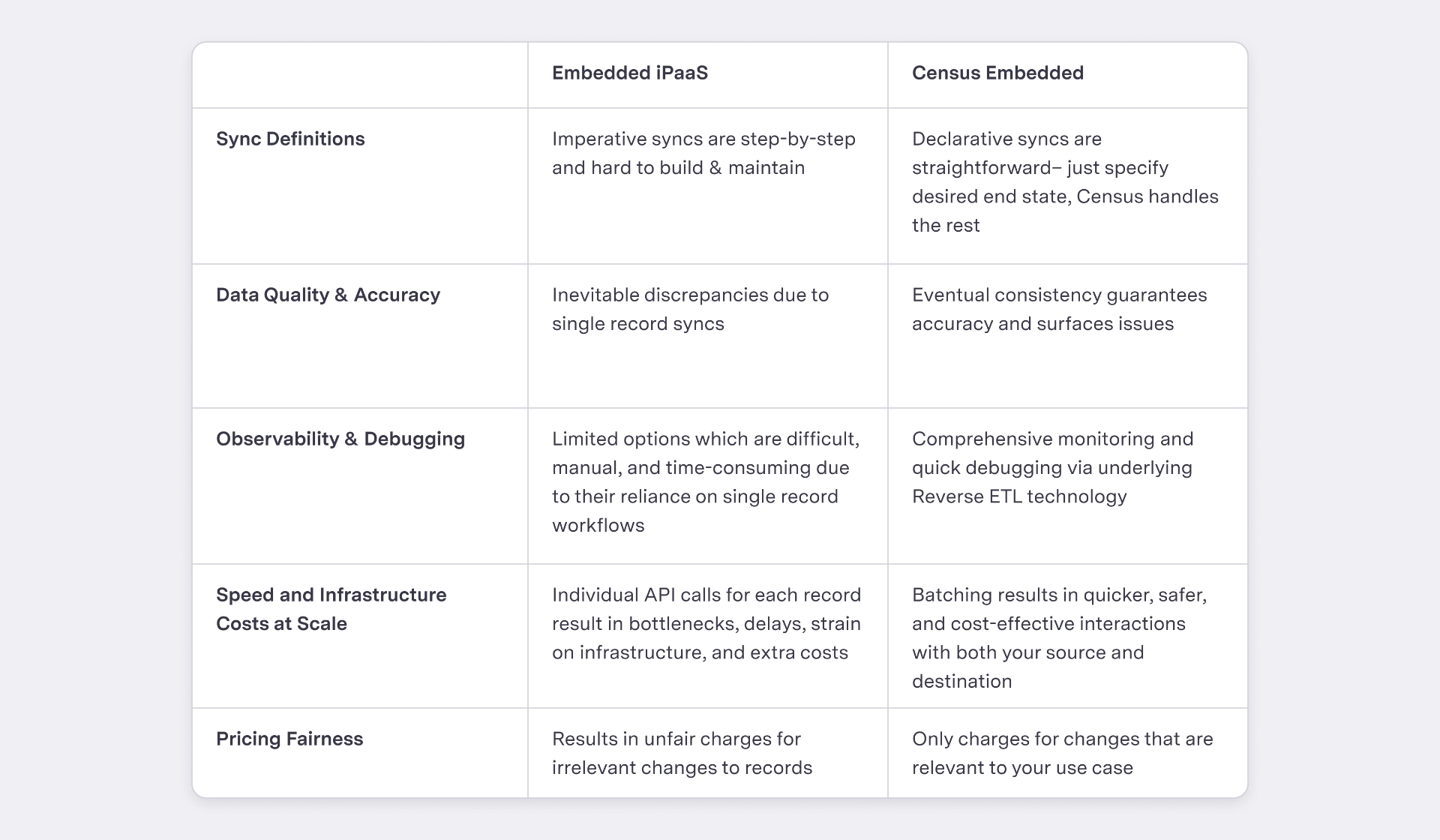
In this blog, we’ll analyze the 5 main shortcomings of Embedded iPaaS:
- Sync Definitions
- Data Quality & Accuracy
- Observability & Debugging
- Speed and Infrastructure Costs at Scale
- Pricing Fairness
We’ll consider their impact on your organization and how Census Embedded alleviates these concerns.
1. Sync Definitions
When syncing data between two systems, what matters in the end is the result. Take this example use case:
- I want the phone number column in my database to map to a specific “Phone Number” column in my CRM.
- I want the email column to be both directly synced to a field called “Email”, and also have the domain show up in a field called “Domain”.
- And lastly, I may want the address column in my database to be split up into “Street Address”, “City”, and “State”.
iPaaS’s imperative syncs are difficult to configure and maintain
Let’s look at how to set this up in an iPaaS tool. iPaaS workflows follow “Imperative Syncing”, which means specifying a step-by-step process for achieving the desired outcome. In an iPaaS workflow, we would start with a single record, then define how to use or manipulate the values in that record to reach the CRM.
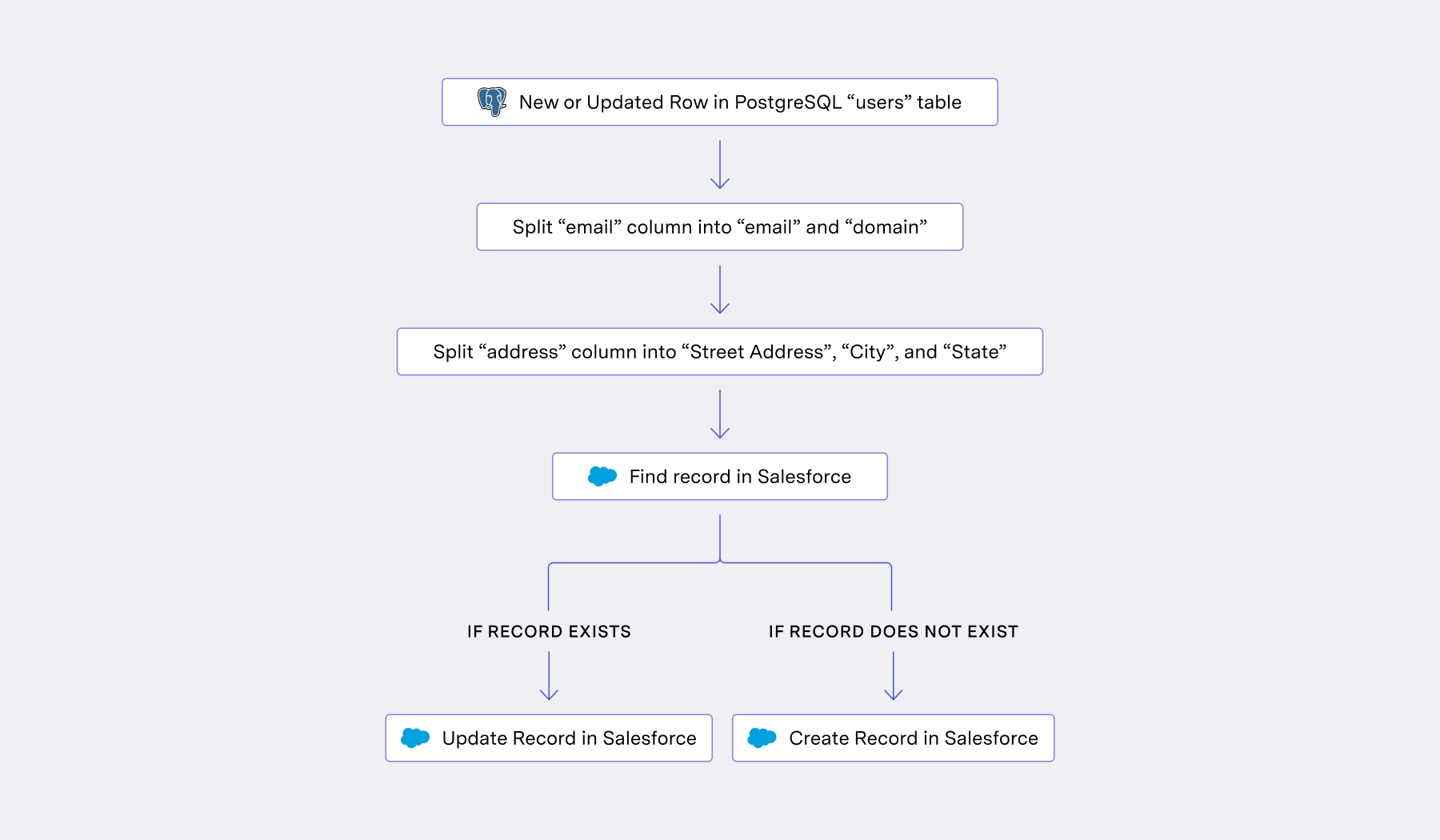
A simple sync like this already requires branching and many chained steps. And this is a basic, run-of-the-mill use case that any organization may have to deal with. The sync will become more and more complex over time to handle never-ending edge cases and requests. Eventually, it becomes tribal knowledge — very few are able to safely step in and update a workflow with branches, many conditionals, and tens of nodes.
Maintaining just one of these can already be difficult when dealing with internal use cases. In an Embedded context, designing and maintaining workflows that depend on shared context becomes even harder. Embedded iPaaS providers take two different approaches to “who designs the workflow” — either your customer, or you — each approach with its own shortcomings.
Embedded workflow designers
Ex: Appmixer
One class of Embedded iPaaS providers is those in which your customers are able to define their own workflows in an embedded view.
At first glance, this feels quite powerful — why wouldn’t I want my users to configure their own syncs?
In practice, learning a workflow designer's UX is disorienting and confusing. Your customers can only achieve the simplest workflows; if they have to do something even minorly complicated (for example, splitting the address field, as referenced above), their user experience can quickly fall apart.
It becomes too easy for your customers to become frustrated, abandon half-completed workflows, or simply write to support after hitting a couple roadblocks. When embedding another app, their UX becomes your UX. And your business suffers from a poor one.
Workflows defined by your team
Ex: Paragon
Another class of Embedded iPaaS providers is those in which you must define the workflows on behalf of your customers. In this flow, your customers typically fill in only some requisite information (e.g. just the mappings) to set up the sync, and those are filled into your workflow definition.
While the complexity of workflow building is obfuscated from your customers, the burden of building and maintaining these complicated workflows is then left to your engineering and product teams. Each time a customer requests a new type of integration, the request will enter a ticketing queue. It will take days to weeks before it gets picked up, and it adds yet another workflow to add to the ever-growing list of workflows to maintain.
Either way, iPaaS is fundamentally the wrong approach
Maintaining imperatively-defined syncs in your integrations solution leads to frustration. Either your team deals with a maintenance burden they were hoping to avoid by buying a solution in the first place, or your customers deal with the same frustration on your behalf.
Census’s declarative syncs have straightforward definitions
Compare this to “Declarative Syncing”, the strategy employed by Census. In Declarative Syncing, you simply declare the desired end state of the data without having to detail the steps to achieve it. Rather than the branching workflow in iPaaS, which can quickly spiral out of control, you’re able to define the sync quickly and concisely, from which point Census just makes it happen.
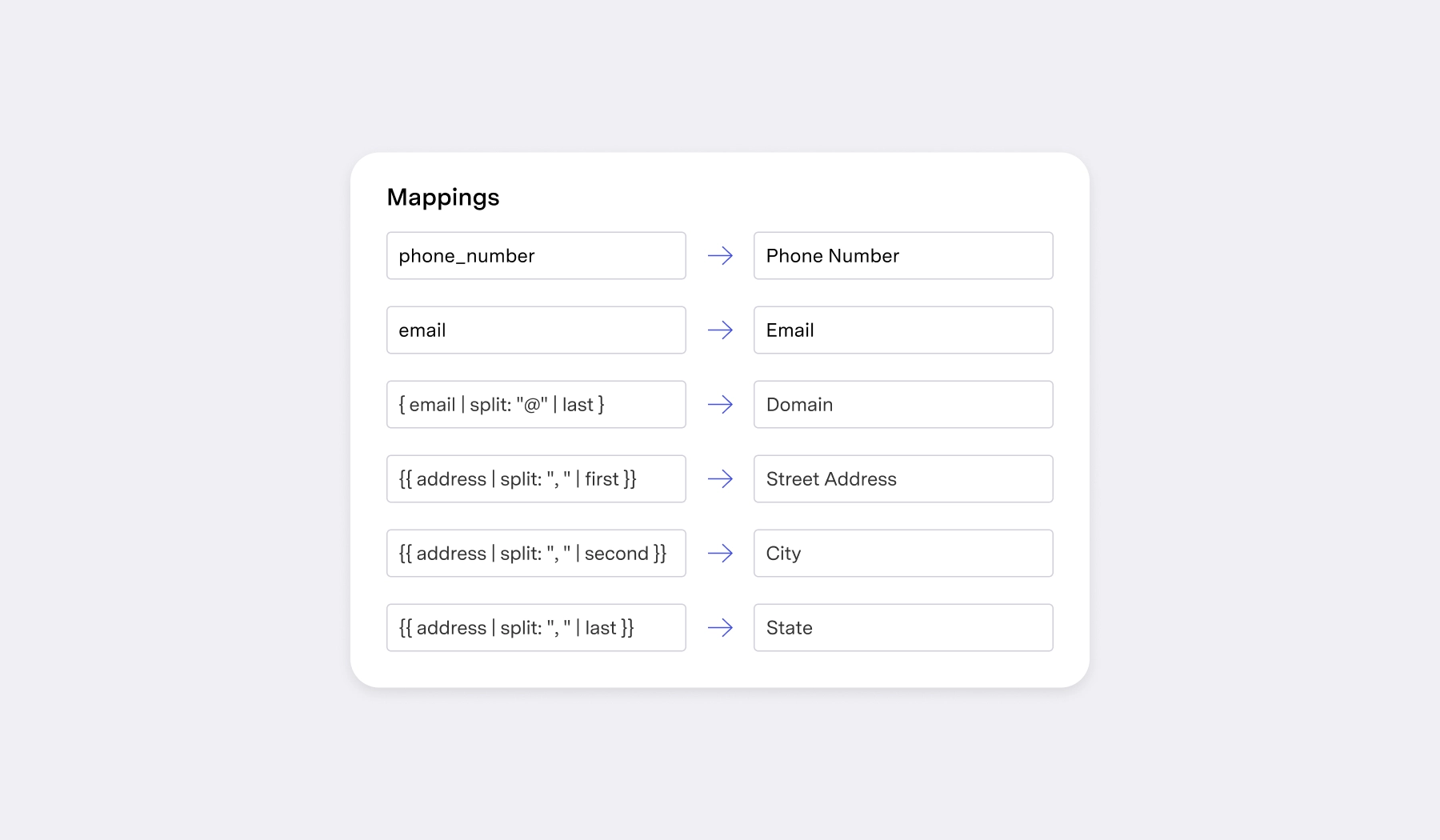
Compared to the imperatively-defined workflow above, this is infinitely easier to read and maintain in the future, whether that responsibility lies with you or your customer.
Declarative syncing works the way we want the world to work. We dictate a result, and the right thing happens. That’s why Census works the way it does.
2. Data Quality and Accuracy
When enabling an integration in your application, your users expect their data to be delivered accurately and completely. When that promise breaks down, and customers start to notice missing data, dealing with the resulting support tickets and poor user experience is debilitating for your productivity and brand. Your integration partner, then, should be doing everything possible to ensure that your data accuracy stays at 100%, keeping your customers happy and your support team unbothered.
iPaaS creates data discrepancies
iPaaS workflows are generally triggered from an action in the source, then process the event or record that triggered the workflow. Operating on a single-record basis means that data accuracy will inevitably drift over time. Let’s take the simplest example:
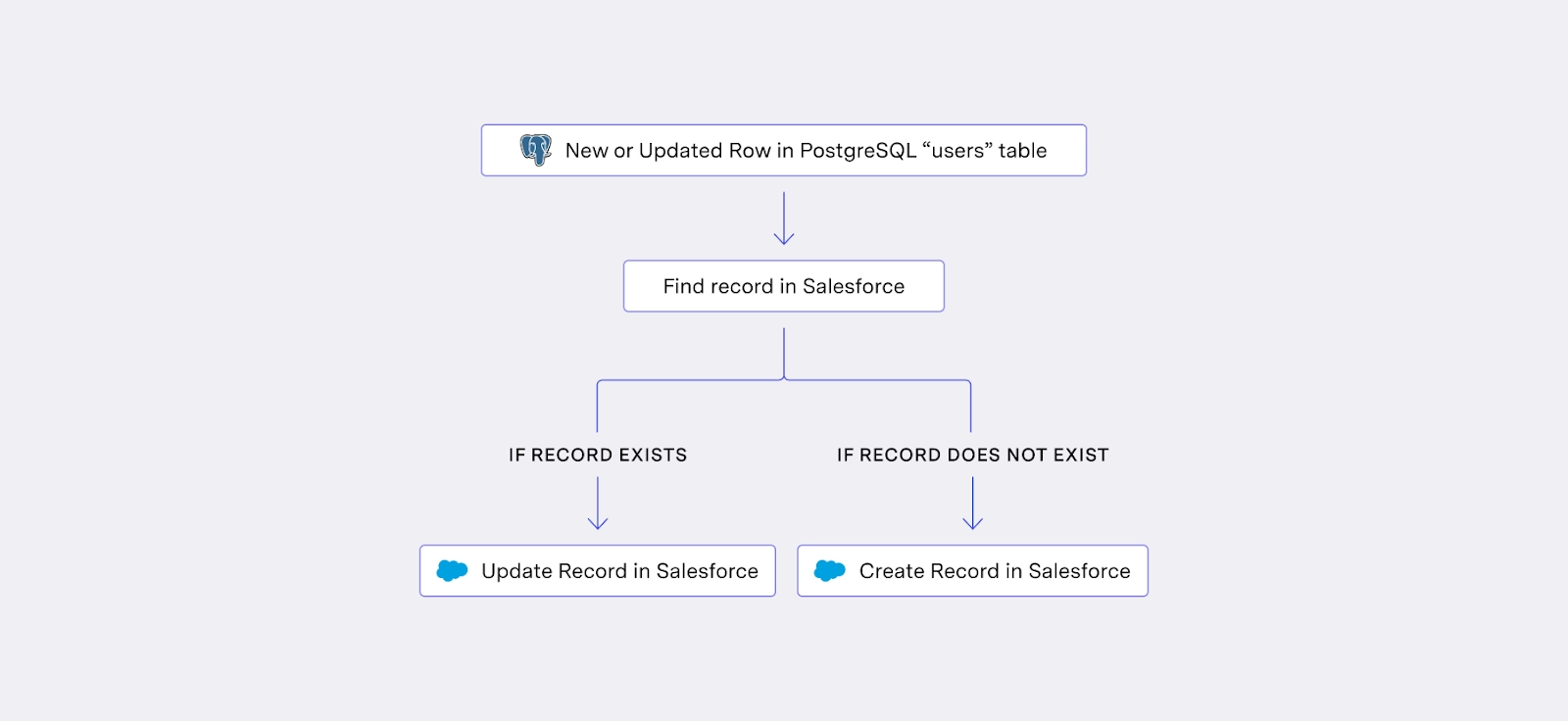
This workflow will detect changes in my users table in Postgres, then find and update the associated record in Salesforce.
In the happy path, this workflow works great. But what happens if during one row’s creation, Salesforce is down for a few minutes, and the workflow never completes? The new user will be permanently missing from my Salesforce contact list. iPaaS makes no effort to keep the source in sync with the destination. Recovery processes, such as setting up a backup or backfill workflow, are left completely in your hands as a user.
In an Embedded context, this can lead to debilitating pain. Data discrepancies can lead to significant customer frustration and support overhead, and are a non-starter for your business. With iPaaS, you’re resigning to data drift between your source and destination, and missing data over time. Customer support tickets can lead to long debugging investigations and loss of trust in your business. It’s a problem that only grows in scale over time, and the impact on your business is extremely painful.
Census guarantees eventual consistency
By contrast, Census utilizes Reverse ETL technology, which attempts to keep your source in sync with the destination on every sync run. This is sometimes referred to as “eventual consistency”. Census will make sure to retry failed records in perpetuity, ensuring you always have a line of sight into keeping your data 100% in sync.
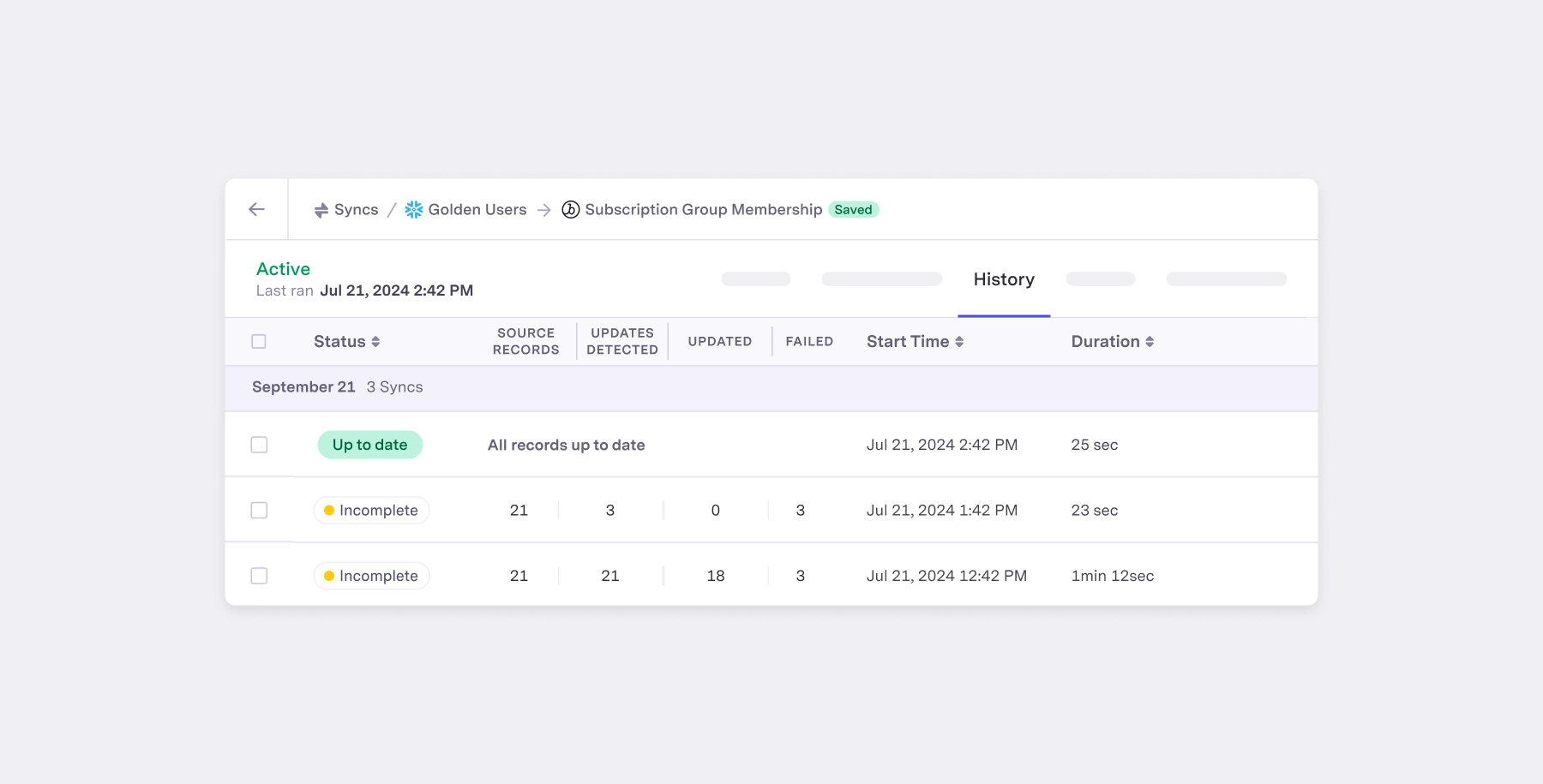
This self-healing capability ensures that missing data will be retried until it reaches its destination and that said missing data will be explicitly surfaced to both you, your support team, and (if you want) your customer.
3. Observability and Debugging
Your engineering team purchases solutions to make your lives easier. This means, first and foremost, a solution should work as expected 99.99% of the time. That’s table stakes.
However, we all know that in software (especially when dealing with big data), things inevitably go wrong. Internally, it’s already important to debug and solve issues quickly. When working with external partners and customers, this rises from “important” to “critical”. Ideally, you want to identify and resolve issues before your customers even notice anything is wrong. If there are issues in your customer’s systems or their permissions, you’d want to surface those issues to them. And when a support ticket does come in, you want all the tools at your disposal to debug the problem.
iPaaS makes simple debugging difficult
iPaas is by design built for single-record workflows. An event happens in the source, your workflow is triggered, and actions are performed.
Unfortunately, this means that debugging is only available on the single-workflow axis. Let’s look at some examples.
Scenario 1 – Single Record Debug
Let’s say a user writes in saying that they expected user12@company.com to have been synced from your app to their Salesforce, but they’re not seeing it. How would you debug?
In iPaaS, the best place to start would be to query or filter all workflows run by company.com that failed. From there, you would have no avenue to look for this specific user. You would have to manually page through all the rejected workflows until you eventually found the one that matches the record you’re looking for — user12@company.com.
In a large-scale integration, this could take a long time, even by API. To illustrate this, imagine that your integration had run 500k times in the last month. Paging through 500k workflows at 25 per page and 300ms per response would take 6,000 seconds, or 100 minutes. Now multiply that by every time you get a support ticket. That’s cumbersome, intrusive to your daily workflow, and not sustainable at scale.
Scenario 2 – Find All Missing Records
Now let’s say a user writes in saying they want a report. They’ve noticed a good amount of missing data over the last couple months, and they feel that many records they expected to be in their system haven't been properly synced (no eventual consistency, remember?). They now want a report of all the missing records. How do you handle this?
In an iPaaS environment, you'd start by filtering all workflows for the given time period to find any that failed. From there, you’d have to download and analyze workflow logs for large batches of workflow data, potentially paging through millions of records over that time frame.
Time aside (which we illustrated in Scenario 1), this would also be complex—a given record could have been processed multiple times, in which case you’d need to determine whether the latest workflow run for that given record was a success or failure.
The sheer volume of data would make this a time-consuming and labor-intensive process. Serving this kind of request is incredibly distracting for your business. You should be focusing on delivering value, not wrestling with your integration provider.
Census is built for high observability and easy debugging
Census Embedded comes with a wide range of monitoring tools through both the UI and the API. The Datadog Integration allows your organization to monitor Census centrally with the rest of your organization’s tools. Flexible sync alerts allow you to monitor not just for errors, but anomalies in runtimes and record counts too. While a sync is in flight, the current sync run status is available. Our sync history allows you to step through previous sync runs and explore the lifecycle of your sync. When you identify a problematic sync run, you can pull either a sample of invalid & rejected records or a full export of every failed record. Within any sync run, you can query any record by primary ID and determine whether it failed or succeeded. We surface API calls in the API Inspector, and we write Sync Logs back to warehouses when requested.
Let’s look at how you would handle the same scenarios we discussed in the previous section, this time with Census Embedded.
Scenario 1 – Single Record Debug
Let’s say a user writes in saying that they expected user12@company.com to have been synced from your app to their Salesforce, but they’re not seeing it. How would you debug?
With Census Embedded, this takes <1 minute. All you have to do is call our Fetch Record API with the primary identifier– user12@company.com, and you’ll instantly get back the record in its entirety, whether it succeeded or failed, and the specific error message if it failed.

This is infinitely faster and can actually be embedded into your application. In a debugging flow, your user could enter an email address and quickly see when that record has last succeeded, what recent error messages were, etc.
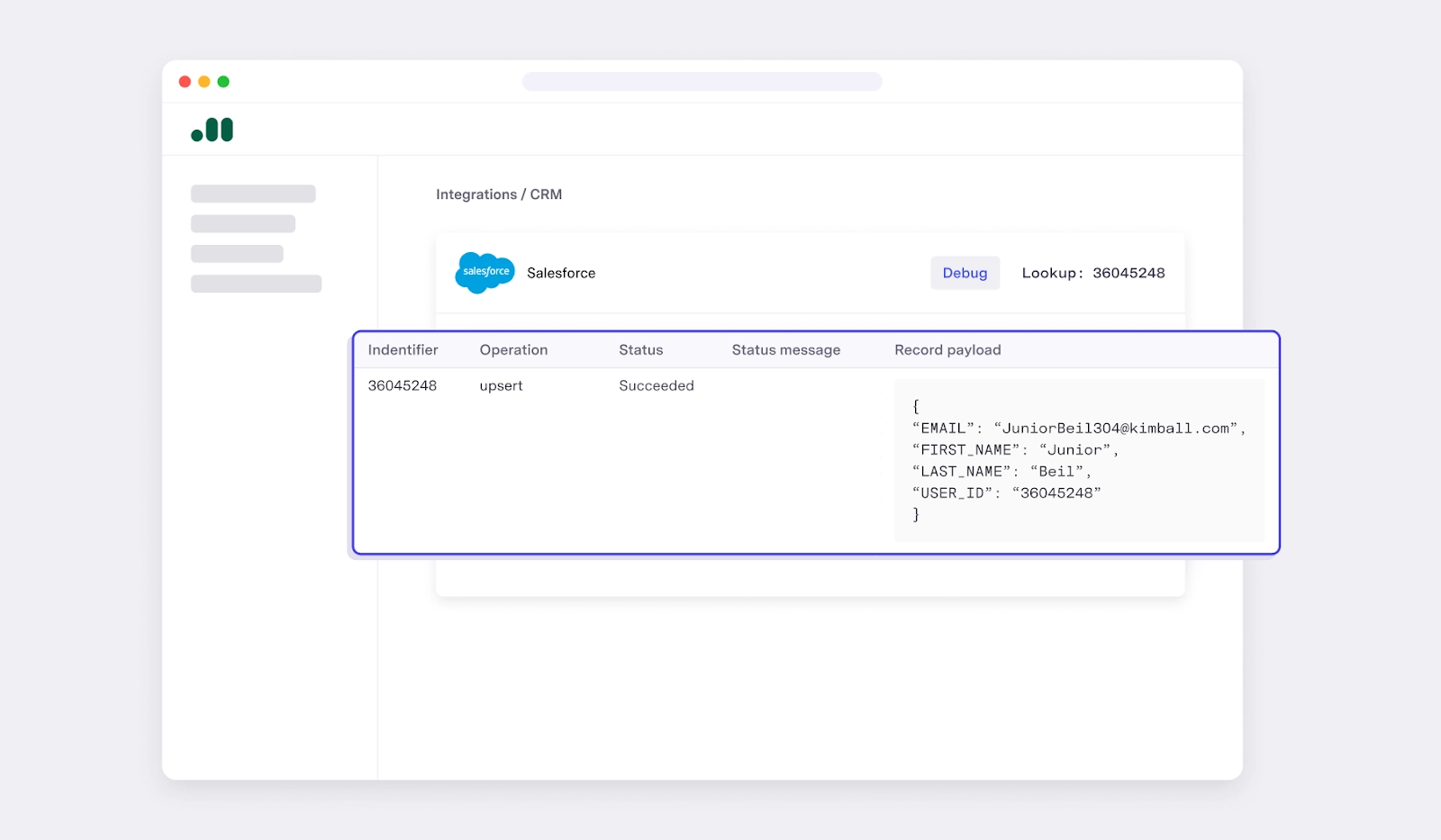
Your support team has to do nothing. Census will instantly tell you what the status of any given record is.
Scenario 2 – Find All Missing Records
Now let’s say a user writes in saying they want a report. They’ve noticed a good amount of missing data over the last couple months, and they feel that many records they expected to be in their system haven't been properly synced. They now want a report of all the missing records. How do you handle this?
In Census Embedded, this is extremely quick. You would simply call the Fetch Records Export API on the latest sync run, which would return a file containing all the failing records along with the reasons why each of them failed.

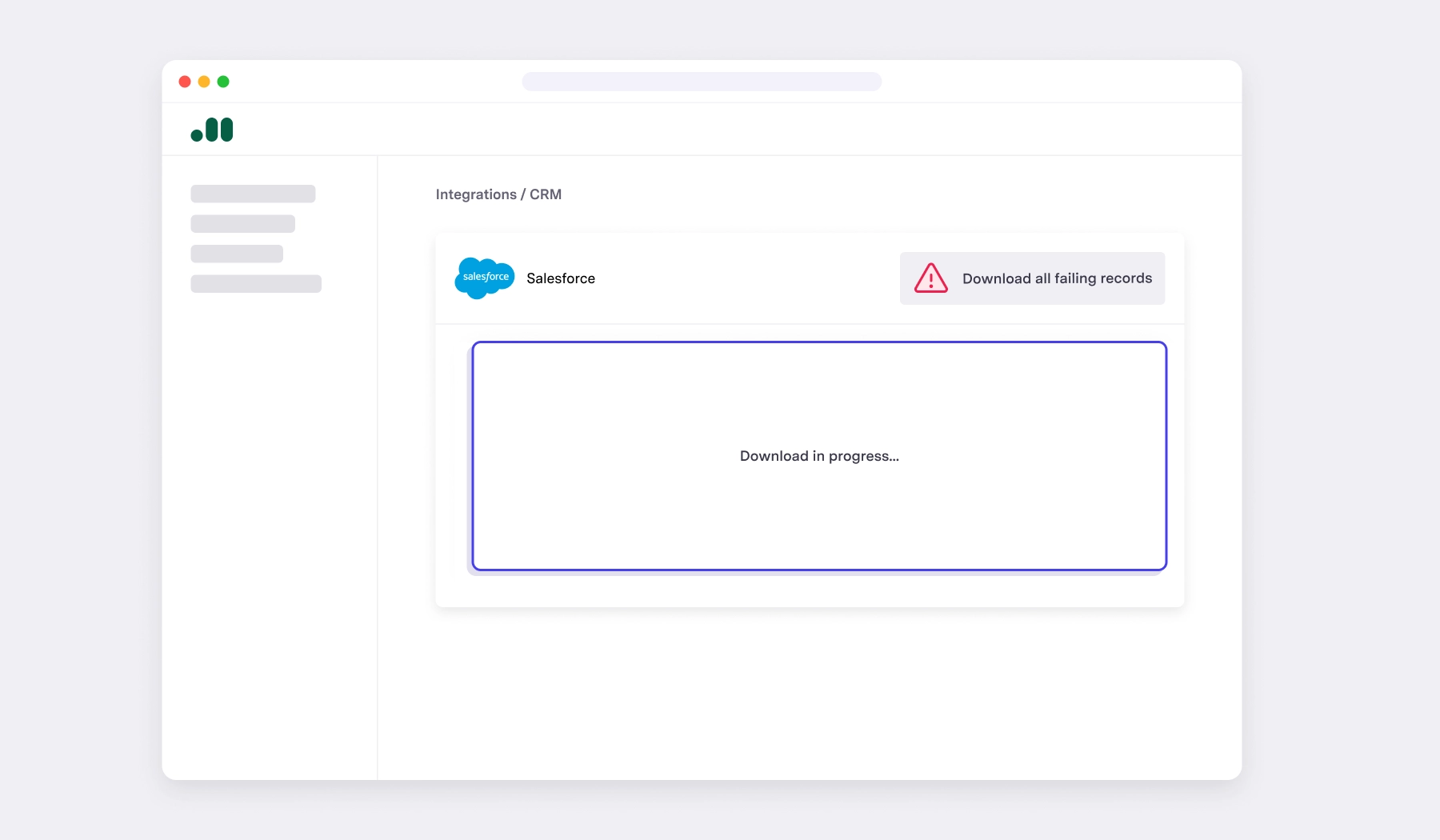
Debugging with Census Embedded is designed to make your life easy. You no longer need to page through thousands or millions of records to diagnose issues. Census is built for observability, meaning that we provide the tools to get you the answers quickly and let you focus on what your business is best at.
4. Speed and Infrastructure Costs at Scale
When you select an integration partner, you’re looking to select a vendor who scales with your needs. As your company scales, the businesses that you work with grow in tandem. Existing customers will be scaling their user bases, and as you move up-market, you’ll be signing bigger and bigger customers with more extensive data needs. The solution that you choose should remain just as maintainable and reliable as when you started.
iPaaS is slow and inefficient at scale
As covered throughout this blog post, iPaaS is built to operate on a per-record basis. Unfortunately, this leads to difficulties scaling on many axes.
Most iPaaS providers do not typically limit the number of concurrent workflows. If 20,000 records change at once, then they are expected to handle 20,000 concurrent workflows to process those record changes. This is great, until you examine the mechanics of these 20k workflows. Because these records are operated on individually, each step in the workflow will be carried out with no volume-related optimizations. That means individual API calls for each record, no batching, no parallelism, and slow transformations.
At scale, this single-record process can shoot your and your customers' businesses in the foot. Let’s observe an example:
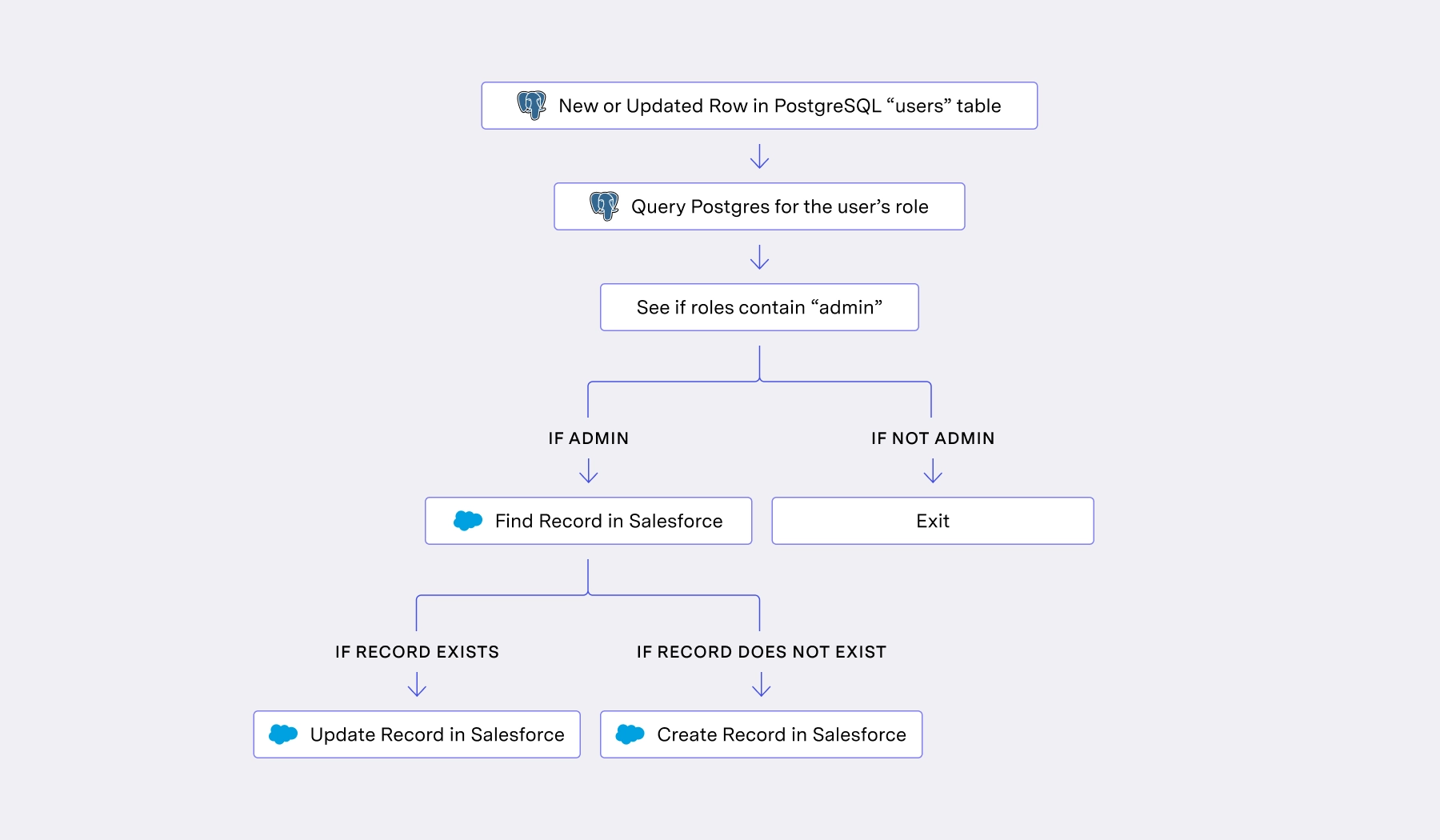
In the above workflow, each processed record must query your Postgres once, make an API call to Salesforce to look up the record, then make another API call to Salesforce to create or update the record.
Across 20,000 concurrently processing records, this means 20,000 attempted connections to your database (which most DBs will reject) and 40,000 Salesforce API calls within a short timeframe. It puts tremendous strain on your infrastructure and exhausts your customer’s rate limits at the same time. Multiply this by many high-throughput customers, and this becomes clearly untenable.
Census is fast, performant, and efficient at scale
Let’s compare this to Census Embedded, which by design is meant to handle massive volumes of data. If 20,000 records change, Census will:
- Open 1 database connection to your Postgres
- Batch Salesforce API calls into groups of 10,000 records, resulting in 2-4 API calls depending on the object being synced to.
For just 1 customer’s integration, we’ve reduced the burden on your database and your customer’s Salesforce by thousands. Performance & efficiency at scale is a huge reason customers prefer Census to iPaaS in internal use cases, and the same is true of external use cases.
5. Pricing Fairness
iPaaS racks up unnecessary charges
Finally, pricing also suffers from the single-record methodology. An iPaaS workflow is generally triggered from the creation or update of a given record. In a pricing model based on workflow executions, then, you’re unfairly punished for irrelevant updates to a source record.
Let’s check out the following iPaaS workflow, which was created to update the address in your customer’s physical mail services provider.
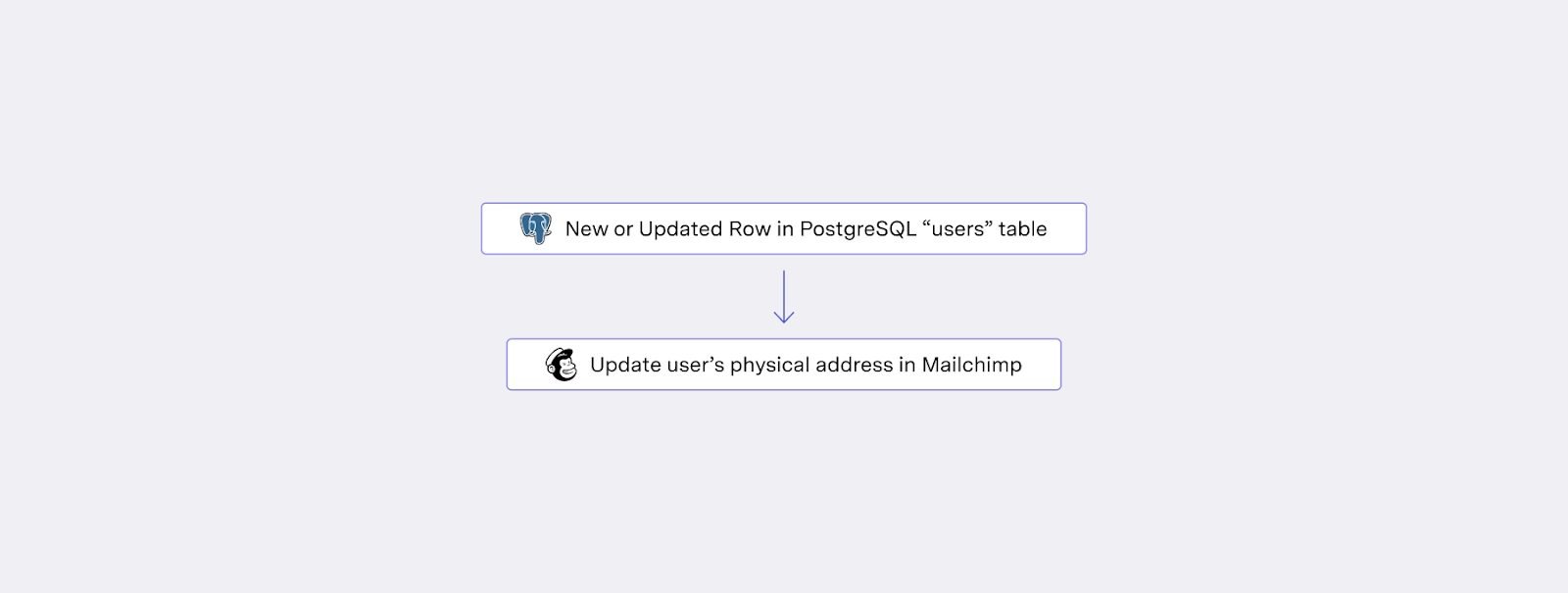
In the above scenario, your workflow will be triggered on any update to your users table. That update could be completely irrelevant—a change to that user’s “in-app preferences” column, for example. Paying on a per-workflow-execution basis is debilitating here—you only care about the address column, but you’re being charged for everything.
Census is cost-effective regardless of data volume
Census, by contrast, only executes changes when it detects changes in the mapped columns.
If any other attribute on the User record changes, Census will simply do nothing. We only act on changes that are relevant to you and your use case, making sure that we’re directly addressing the value you’re hoping to drive.
The Choice is Clear
Your choice of integration solution will define your user experience for years to come. Promises to customers require the most robust, observable, low-maintenance, and accurate integration tools. That is exactly where Census Embedded and Reverse ETL excel. Choosing the right tool ensures your business can deliver on its promises, maintain customer trust, and scale efficiently.
With Census Embedded, you are equipped with a solution that provides unparalleled data quality, accuracy, and observability, making it the clear choice for any business solidifying its data integration strategy. To learn more read our developer documentation or schedule a tour and we’ll help you get started.