

































Late nights, long hours, and a constant string of tickets and feedback are the reality for most data and IT teams today. As every company’s appetite for data grows, technical teams are forced to scale up support to ensure that the right data lands in the right place. But it doesn’t stop there.
Data teams are expected to provide actionable insights, comprehensive data governance, and compliant datasets for their entire organization while juggling new technologies, unclear expectations, and an ever-growing volume of data. Data teams are overwhelmed, business teams are confused and anxious, and everyone is spending more time discussing processes and procedures — and less time innovating.
Data stress is real, and everyone feels it.
More data, more requests, more stress
Everyone has more data than they know what to do with, and data stress is a big reason why every organization’s capacity to turn data into impact remains limited.
There are 3 main causes of data stress:
- Incomplete or siloed data: The average business uses 367 software apps, and each app produces its own siloed data. Unifying data in a data warehouse or data lake is an important first step, but there are other sources like streaming data or third-party data that need to be included to establish a comprehensive source of truth.
- Lack of collaboration: Who hasn’t gotten the dreaded “Can you just pull this audience for me by tomorrow, should only take five minutes” message? Business teams are often too far from the data to understand what’s possible and how to articulate what they need. When data requests and tight deadlines pile up, business expectations get lost in translation, resulting in multiple back-and-forths and a lack of confidence.
- Poor data quality: Unifying data requires joining data from different sources, in different formats, and at different intervals. Enriching and moving data can cause errors, inconsistencies, and duplicate records, which impact your speed of delivery and credibility of insights. It’s difficult to get a full picture of which data is correct.
So, where do we go from here?
Census Datasets: More collaboration, better data, less stress
No magic prescription can solve all your problems, but today’s introduction of Datasets kicks off our commitment to reducing data stress.
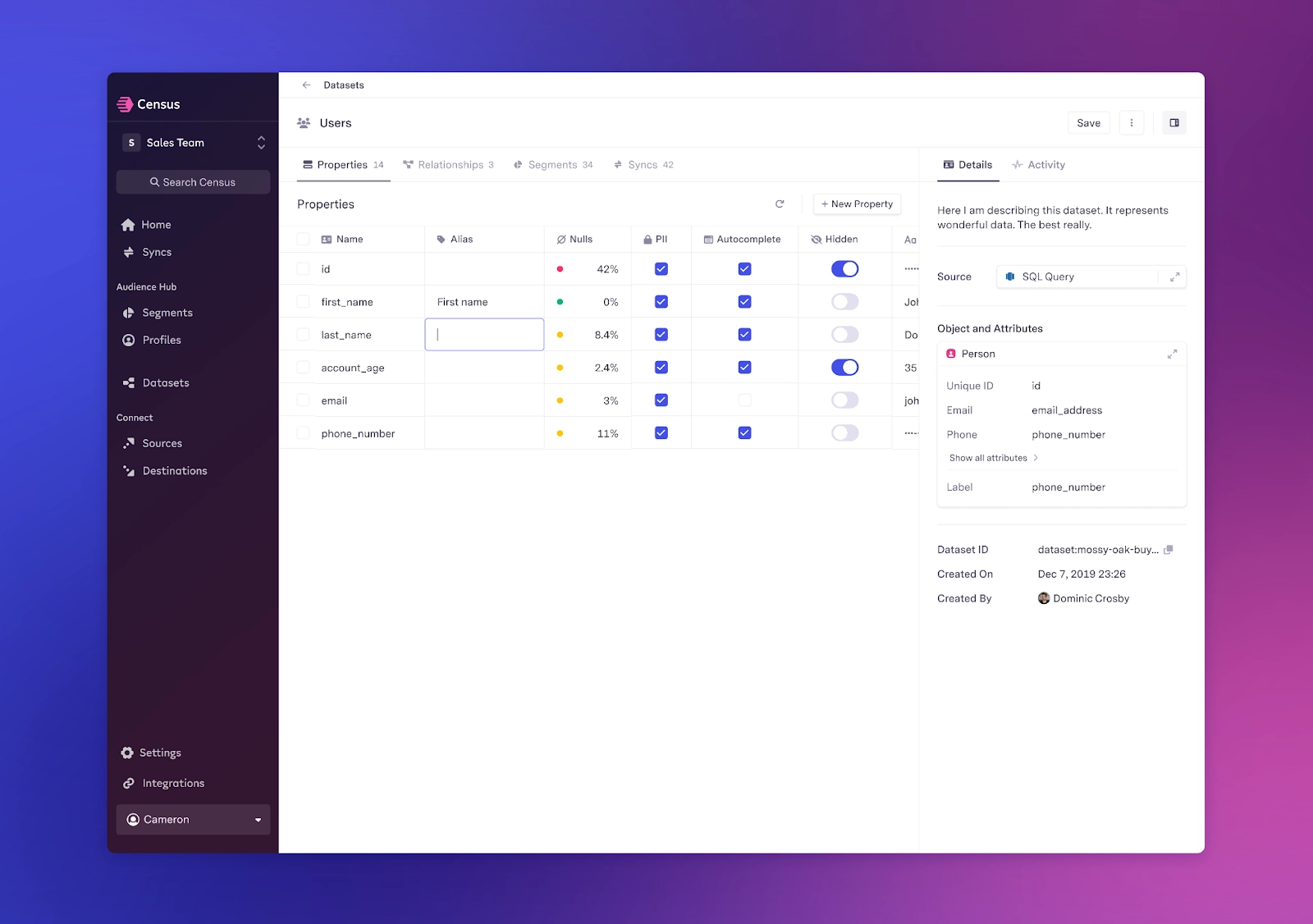
Census Datasets create a shared, singular view of trusted data, simplifying data exploration and modeling. This helps every user sync data with confidence and reduces the stress of data management.
|
Today, Datasets are available to every Census user. Over the next six months, we'll build more features to help data teams unify, govern, and validate data, making it easier to activate any dataset across 200+ business tools.
Our vision of how Datasets address the causes of data stress:
1. Making data complete and overcoming silos
Datasets provide a more powerful way for businesses to expand and enrich shared data definitions. In the past, data teams had no way to view and discover all their data sources in one place.
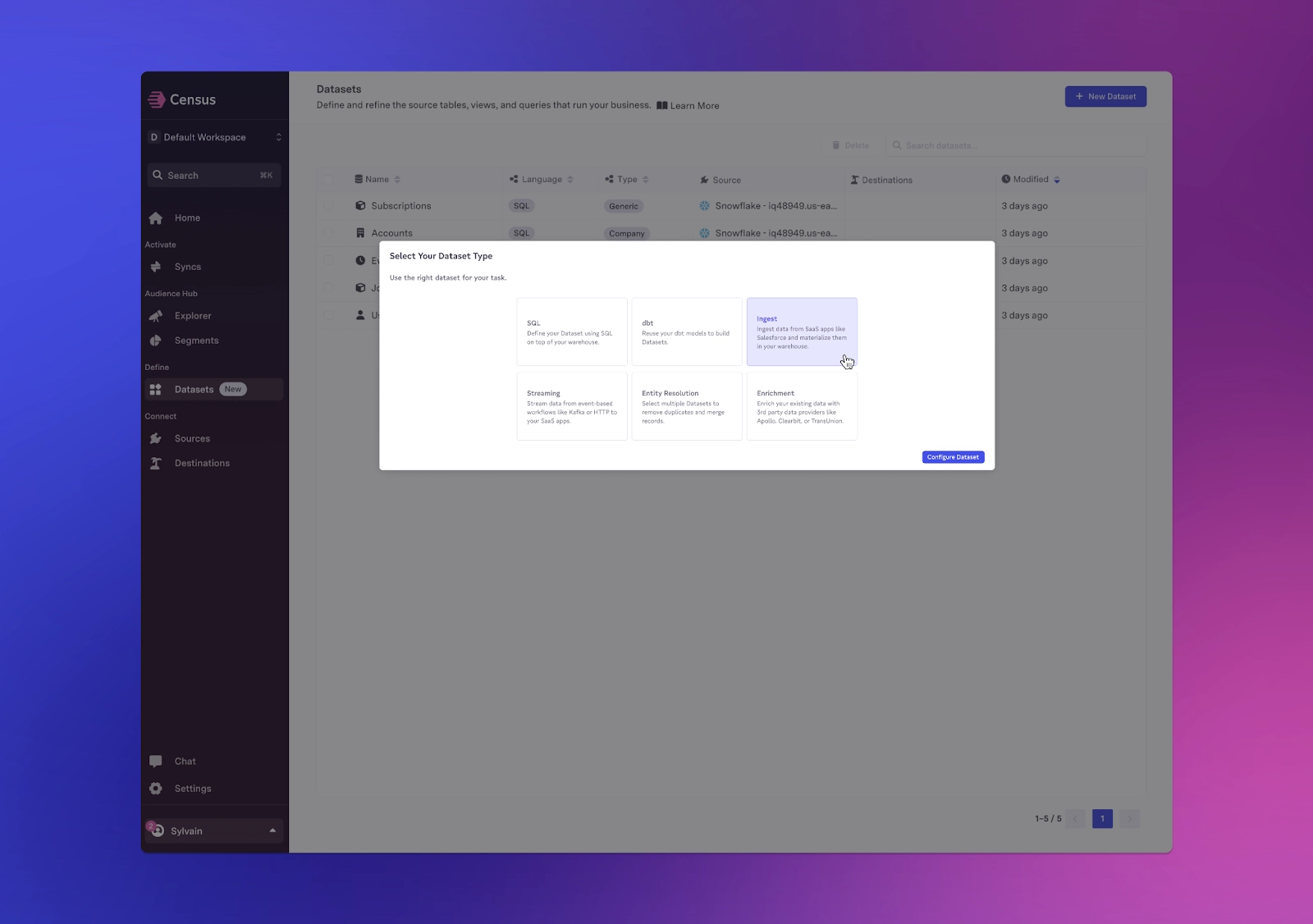
Datasets are unique because Datasets can be joined with other Datasets and enriched with custom properties like custom calculated fields and formulas, all within Census. In Datasets, you can expose models using SQL, dbt, Python, Looker, or Sigma. You can also add Streaming Datasets from HTTP, Kafka, or Confluent Cloud for real-time event streams.
 |
Enrichment Datasets
Coming soon are Enrichment Datasets, which enable you to add more data to Census to create a complete picture of any business object by ingesting data from third-party data sources like Apollo, Clearbit, and TransUnion.
2. Creating a collaborative workspace for data:
We designed Datasets to be the ideal place for collaboration between data teams, who speak SQL, and business teams who need data for campaigns and experiments. Datasets help business teams get closer to their actual data and reduce the back-and-forth on data requests.
Computed Columns
Using Computed Columns, business and operations teams can directly add custom calculations and customer properties to shared Datasets. We make it extremely easy to perform last-mile data transformations like creating a column for lifetime value or adding company size to leads.
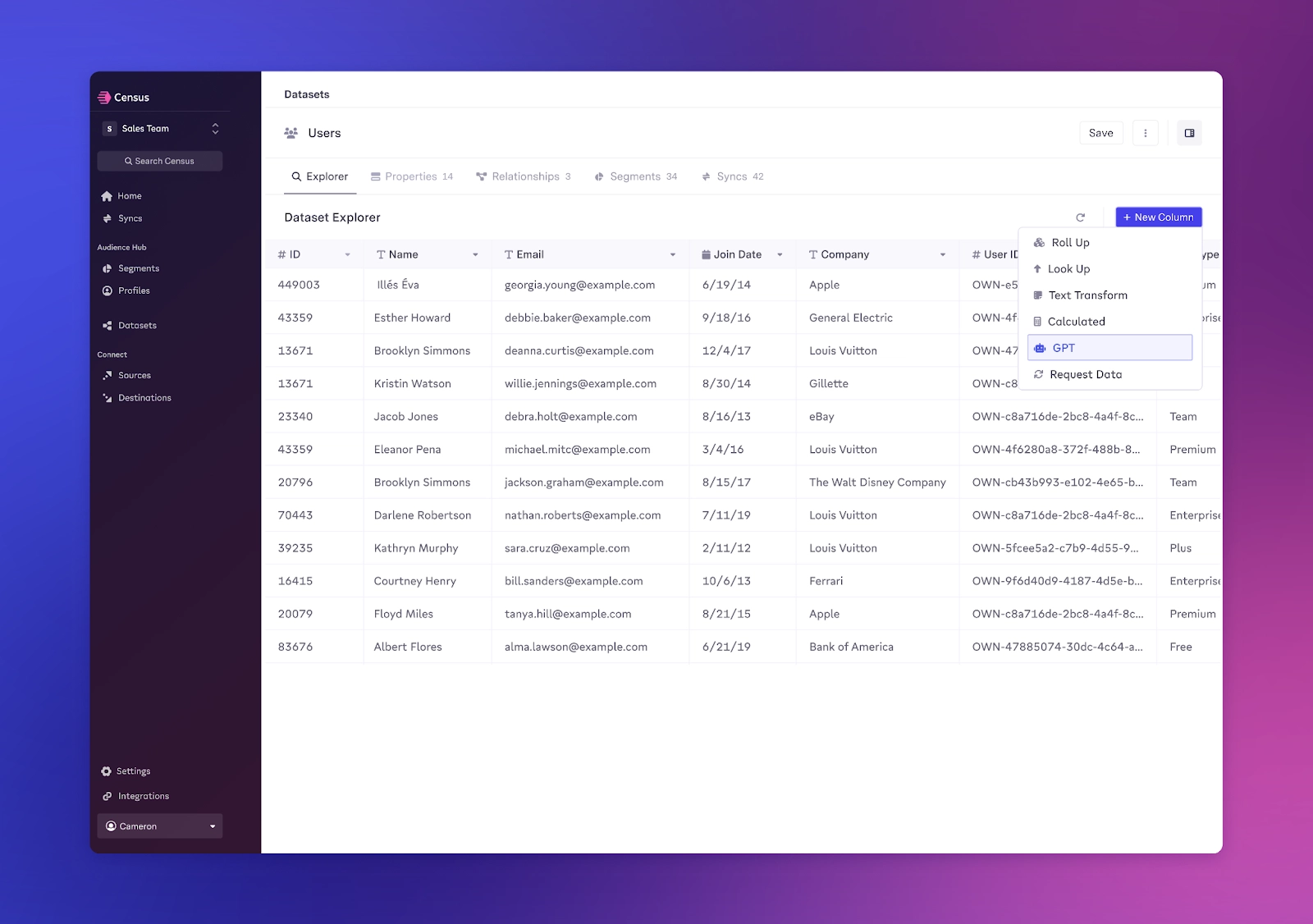 |
We provide 3 types of Computed Columns, with more coming soon:
- Rollup Columns - Allow you to find count, sum, min, and max values or records from related datasets
- Text Transform Columns - Use Liquid Templating to do text transformations (and more)
- Calculated Columns - Allow you to calculate differences, averages, and changes on related datasets
Data Request Columns:
Coming soon are Data Request Columns, which extend the collaboration abilities of Datasets. Business teams who need additional data or more help can use a Data Request Column, which creates a task for data teams to provide the right data. This seamlessly integrates with existing data team workflows, whether they use Git, Jira, Slack, or something else. Once done, requesters will be notified and can use the new data immediately in syncs or segments.
3. Improving data quality
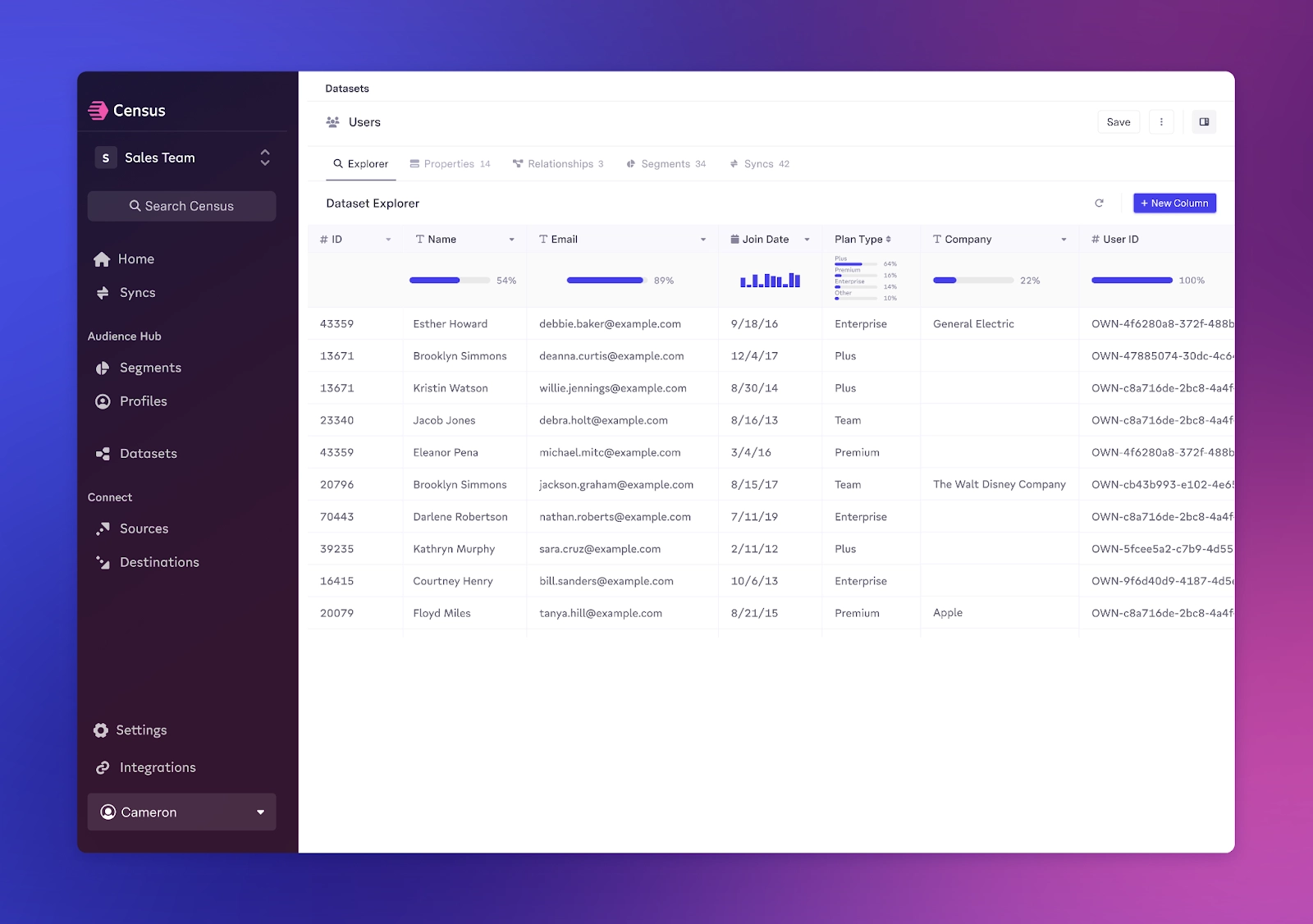
Dataset Explorer
The Dataset Explorer is a single pane of glass that helps both data and business teams view all of the information that Census has access to. Also, one advantage we have over classic data lineage tools is that Census knows which data is synced to which downstream destination, helping you see all your data activation flows in one place and verify that they’re correct.
Coming soon to the Dataset Explorer is the ability to see data health metrics like fill rates and metadata.
 |
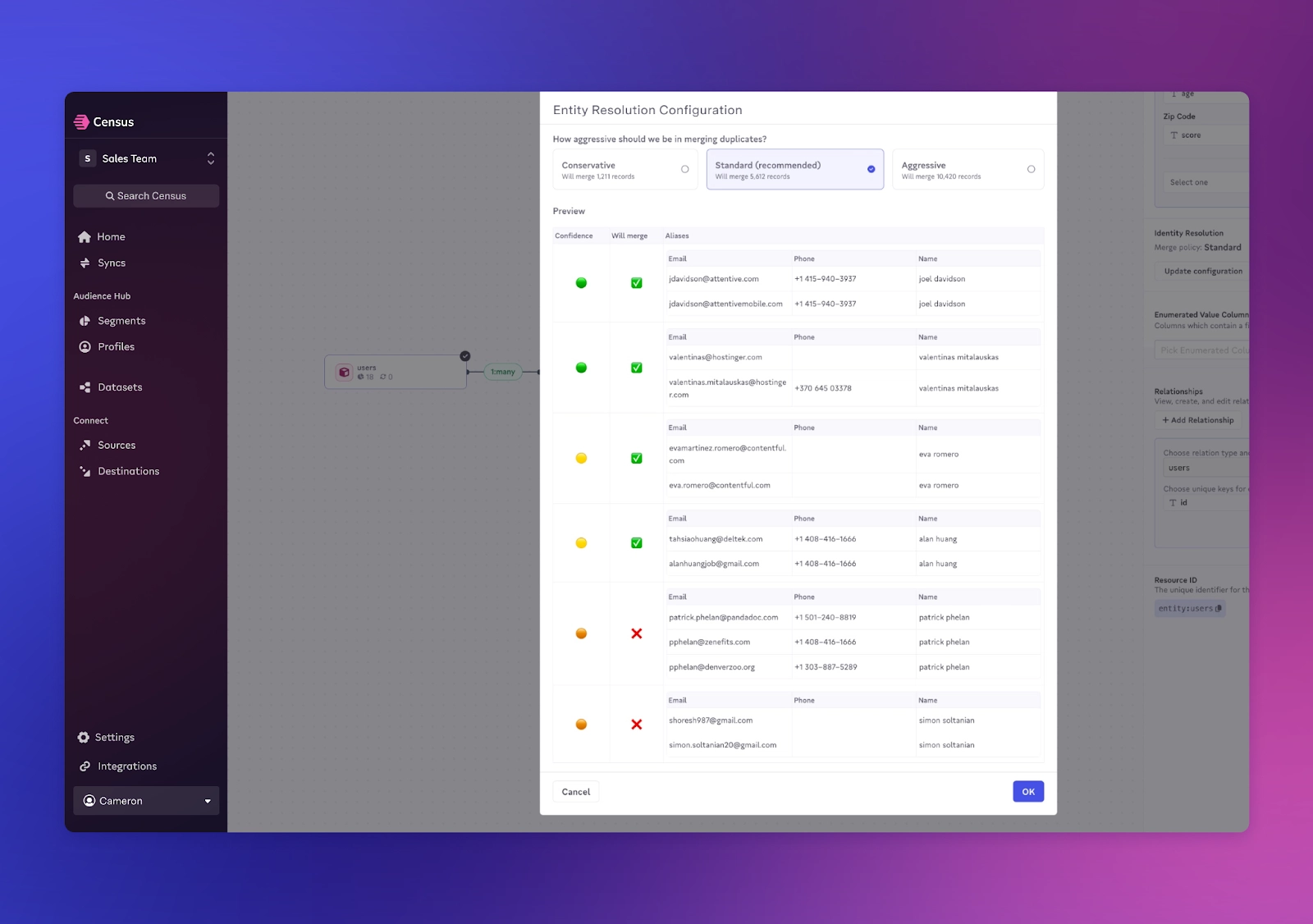
Entity Resolution
Coming soon is Entity Resolution, which enables users to identify and merge records in multiple Datasets. This is a holistic way to clean and maintain large datasets across all business objects, encompassing use cases like identity resolution.
 |
Data Transformation supports Data Activation
Datasets improve usability by creating a trusted, single view of data that can be synced or segmented without any limitations.
After defining a Dataset, anyone can immediately leverage it in every part of Census:
- In Reverse ETL syncs (including real-time Live Syncs) to trigger the right messages at the right time
- In Audience Hub to build granular segments that enable hyper-personalized emails and ads
- Via the Dataset API to power next-page personalization on websites, real-time recommendations, and even internal tools.
Get started today
We’re excited for you to try out the new Datasets experience, which provides data teams with more capabilities to overcome data silos and quality issues. Over the next 6 months, we’re committed to building more features that empower data teams to transform and govern data and business teams to contribute to a trusted data layer.
Datasets are available now. Get started with a free 14-day trial or reach out for a personalized onboarding.