































At 3,168 words this post is considered a big one! Take a cup of tea 🍵 or coffee ☕, relax and enjoy the read.
If there’s one lesson to take away from 2020, it’s this: anyone making bold predictions for the future doesn’t know what they’re talking about. Lots of predictions have been made about data and the future of data teams, but the truth is that the “data industry” is way too new and nuanced to make good, solid predictions. Especially in light of 2020.
How do you build a data team these days? And how do you equip your data team to weather whatever storms the ’20s have in store? The best thing a company can invest in (besides the data team itself) is a set of tools that allow for flexibility, so you can adapt to whatever the future of data throws at you. And the best way to know if you’re investing in the right data tools for your data team is to pay attention to the current trends.
We’ve identified a few trends in the world of data and tried to draw out some useful takeaways. Of course, take these trends with a grain of salt. In May, aliens might land to sell us all on the newest, coolest data warehousing technology.
1. Data Is Easier to Work with Now
Ten years ago, the tools we used to work with data required quite a bit of effort to learn. But recent advancements made by a few data tools have made working with data much less of a headache. There are two ways modern data tools make things easier: cloud-based architecture and automation. Both have changed the modern data stack and how teams work with that stack.
Cloud-Based Solutions Streamline Setup
Building a tech stack with cloud-based data solutions has gone from taking two weeks to around 40 minutes—with the flexibility to alter that tech stack as needed.
The shift to cloud-based architecture was led by Redshift in 2012 or so. Rumor has it they landed on the name Redshift because they wanted to shift people away from Oracle’s on-premisedata warehousing (which was primarily branded with the color red).
An ecosystem of cloud-based data tools quickly grew around Redshift, which Tristan Handy, CEO of Fishtown Analytics, described as a “Cambrian Explosion.” This ecosystem allowed data teams to work with data using minimal overhead.
But the process of spinning up a data stack at this time took at least a two-week sprint period. And that didn’t count the vetting and internal buy-in for each tool because, at the time, some cloud-based tools were known to lock businesses into long-term, expensive-to-break contracts. You had to be double-triple sure what you were investing in would be good for years to come.
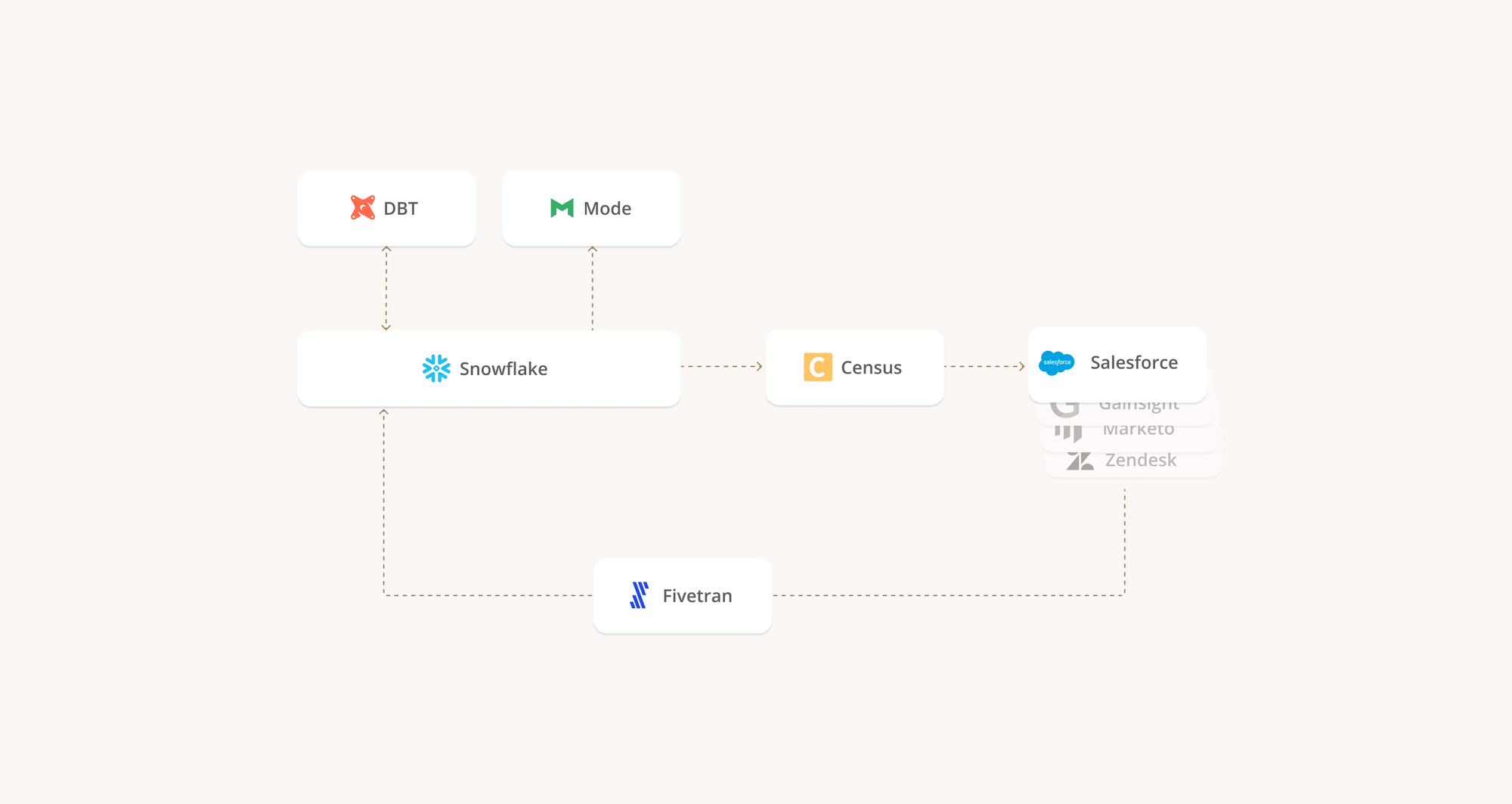
We’re currently in the midst of a new ecosystem forming. And these new tools are starting to outcompete the old guard. This ecosystem is forming around Snowflake, with tools like dbt, Fivetran, and Census (of course 😉) starting to make a name for themselves.
This newer ecosystem of tools is starting to show the true potential of a cloud-based data stack. And the initial results are pretty astounding—Seth Rosen at Hashpath recently proved that you can spin up an entire data stack in under an hour. Granted, you don’t really want to rely on a data stack that you spent 40 minutes creating, and you don’t necessarily want to change it around on the fly, but the fact that it’s possible reveals the amount of work that’s been offloaded from the shoulders of data teams.
Automation Is Causing a Philosophical Shift Toward Treating “Data as Code”
As the processes and infrastructure for delivering data become more and more automated, data management is starting to go the way of DevOps. This transformation is already underway with the rise of concepts like operational analytics and tools like dbt and Census.
Now, there already is such a thing as DataOps. The problem with DataOps though, is that, as Arrikto CEO Constantinos Venetsanopoulos says in his recent article, it doesn’t solve for the “request-and-wait cycle.” You still need to request the data you need and then wait for someone to serve it to you.
In contrast, operational analytics automates the delivery of data from your data warehouse directly to the tool and person that needs it. AsJamie Quint put it, you can “push data back out to Salesforce for our sales reps, Facebook and Google for custom audiences, or Google Sheets for a growth model.”
The new ecosystem of tools outlined above naturally facilitates this workflow, with Fivetran ingesting data, Snowflake storing it, dbt transforming it, and Census sending it where it needs to go. You can visualize this relationship as a hub and spoke, where the hub is Snowflake and your SaaS tools are the spokes, while dbt, Fivetran, and Census manage the connections from hub to spoke.
With this framework you can start to, as Constantinos puts it, “treat data as code” with CI/CD (continuous integration and continuous deployment), versioning, collaboration across the cloud, and more. We’re smack-dab in the middle of a philosophical shift in the way businesses manage data, and its been brought on by automation provided by the new ecosystem of data tools.
👉Read more on Why Data Team Should Care About Operational Analytics
The Upshot: Better Data Tools Mean Better Data Teams
The newer and improved cloud-baseddata tools reduce the workload of both the initial setup of a data stack and the daily responsibilities faced by data teams. And data teams can take the time they used to spend managing the minutia of data infrastructure and dedicate it to thinking deeply about how to improve their data processes, as well as the infrastructure.
Drizly’s Emily Hawkins, data infrastructure lead, and Dennis Hume, staff data engineer, recently gave a talk at Fivetran’s Modern Data Stack Conference on how Drizly completely revamped their data team in 2020 with the newer breed of cloud-based data tools.
The data team at Drizly started with a legacy Redshift-based data stack that was bloated and expensive. It worked. But could it work better?
Emily walks you through all four phases in their webinar (it really is worth a watch), but in summary: within a few months, she had led her team to a stack that included Snowflake, Fivetran, dbt, Census, and a few other tools.
A few of the benefits she directly calls out:
- With Fivetran, their data engineers don’t have to babysit ETL flows anymore.
- dbt’s “library” approach allowed their analysts to “think and work much more like software engineers.”
- The entire stack allowed them to "standardize workflows and automate staging environments for easy experimentation."
But here’s the thing: Drizly is an alcohol delivery company. During the pandemic lockdown, their business boomed. Could they have handled this situation with their old data stack? Probably. But with the new data stack, they felt none of the growing pains they expected to feel.
Dennis explains that it was generally smooth sailing for Drizly’s data team. They weren’t bogged down with the minutia of scaling their data stack. It adapted to their needs as they arose, so the data team stayed focused on the bigger issues, like helping other teams keep up and improving the product along the way.
This is an example of what modern data teams can expect out of their data tools. These new tools will take more and more of the grunt work off the data team’s plate, so they can focus on larger, hairier problems—like helping their organization adapt to the craziness that was 2020.
2. “Unprecedented Times” Means Disruption
Alright, here’s the inevitable “unprecedented times” section. 2020 has been crazy, and data teams haven’t been spared from this craziness. A few trends have arisen as a result of stay-at-home orders. It’s too soon to say for sure what the impact of these trends will be long-term, but they’re worth paying attention to.
Remote Work Can Change Day-to-Day Routines
Being physically apart has increased everyone’s reliance on asynchronous communication. The lack of in-person face time means that a few traditional processes may not come back—at least not in the way they were in the “before times.”
One casualty may be in-person daily scrums. Threads points out that daily scrums via Zoom can take longer than they would have in-person. That small amount of daily friction can build up over time and lead teams to move towards asynchronous scrums located in a dedicated Slack channel. Doing scrums this way removes a recurring meeting from everyone’s calendar and gives your data team increased control over how they spend their days.
Ad hoc requests may also make a move to dedicated Slack channels, if not direct messages. The good thing here is that without the face-to-face urgency of the ad hoc request, your data team might have room to push back on the immediacy of the request. This push back can help your team focus on the roadmap.
Overall, asynchronous communication provides individual team members with more control over their time, while less face-to-face ad hoc interruptions can improve the focus on core long-term initiatives.
A Location-Agnostic Approach Broadens the Talent Pool
Remote-first work will change the makeup and structure of data teams, especially for big companies. There will be a larger (and younger) talent pool as teams become fully remote and location-agnostic.
A remote-first approach moves attention away from Silicon Valley and towards the “Silicon Slopes” and the “Silicon Prairies” of the world. The pool of candidates that companies are hiring from is no longer limited to people willing and able to relocate to the Bay area or any other traditional talent hub.
This reality is already having an impact on larger teams. Shopify’s CTO says they’re going to start building their technical teams by time zone rather than by city. And this seems to be a smart move as distributed teams from companies like Auth0 and Segment say that much of their innovation is driven by their distributed structure. In short, distributed teams can draw from a wider talent pool and are likely to innovate faster.
The Upshot: "Traditional“ Methods Are on Their Way Out
The shift to remote work has kick-started a fundamental rethinking of how data teams approach everything, from daily routines to recruitment. In the end, we’ll see new ways of managing workflows emerge, as well as increased innovation incubated from a larger talent pool.
Agile methodology will stick around, but data teams that use it will find ways to trim the fat, like starting to eliminate Zoom meetings. The team will be more remote, diverse, and focused on their work—no in-office distractions or requirements to move to the HQ city. All of this will require a rethinking of how a data team functions together using its stack of data and workflow tools.
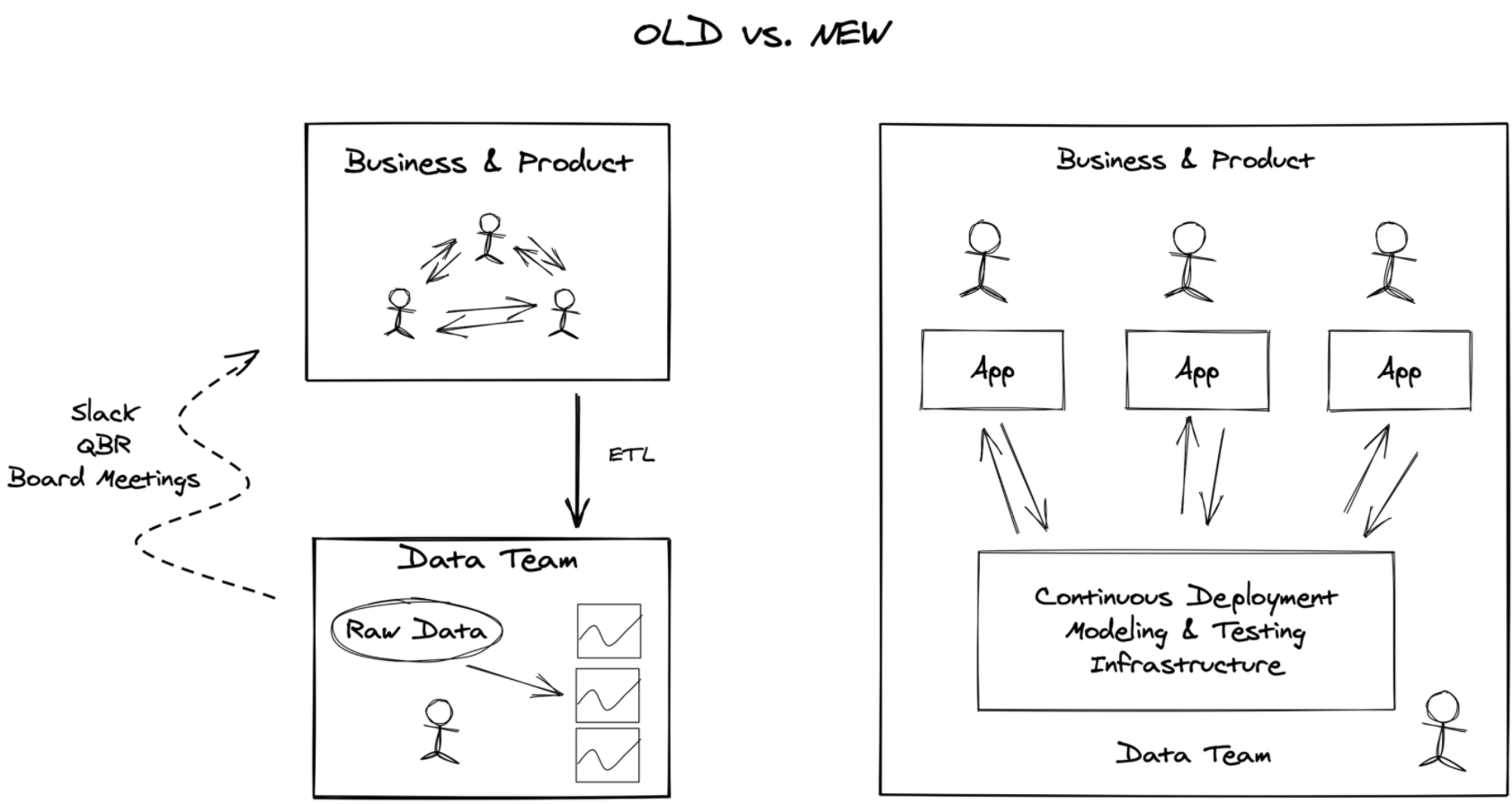
3. Data Team Roles Are Changing
The structure of the data team is changing in response to new tools, increased interest and investment, as well as remote-first work. Old roles will change while new ones gain prominence.
Data Engineering Has Changed
Data engineers are no longer needed to start a data team. Because it’s so much easier to set up and maintain a data infrastructure with today’s data tools, the purpose of the data engineer has shifted to the point of being almost unrecognizable.
Data engineers were traditionally the very first hire, and their job was clear: create and maintain the data infrastructure. You would then hire people to work with that data, like data analysts and data scientists. Now, modern data tools have reduced much of the infrastructure work data engineers used to do. Instead of just focusing on data infrastructure maintenance, data engineers can now empower everyone who works with data to use it well.
There’s now a legitimate question of whether you even need a data engineer to get your data efforts off the ground. Tristan at Fishtown Analytics argues no—and we’re inclined to agree. Analysts can now get things rolling on their own without the need for heavy engineering work. And, as Chartio argues, you might not even need analysts to get started with data at your organization.
Modern data tools are slowly changing the role of data engineers, and that has a huge impact on how data teams are built.
Specialized Roles Are Here to Stay
Not everyone working with data needs to know the details of your data infrastructure. The removal of this barrier allows for more specialized roles that don’t need to take the intricacies of your data into account in order to use it well.
Bringing back the Drizly example from earlier, Emily and Dennis explain that, with their new data stack, they can staff data analysts who focus solely on specialized areas, like marketing or sales. These analysts don’t have to worry about the flow of the data they use—they can focus on the job to be done rather than the mechanisms behind that job.
This job-to-be-done focus gave rise to specialists who could maintain a laser-focus on their specific area of expertise. How specialized these roles get is totally up to the specific needs of the business, but no matter what they end up being, they’re made possible with the newer crop of data tools.
The Upshot: Be Prepared for New Data Roles
The roles on data teams will start to hone in on specialties, while the roles that traditionally focused on generalized data infrastructure will turn their attention to empowering these specialists. The new data stack makes this shift possible by simplifying the processes of creating and maintaining the data infrastructure.
A good example is the rise of the analytics engineer. The analytics engineer is, at its core, an analyst who can help themselves (and help others)to the data they need. It’s like a hybrid of the traditional roles of data engineers and data analysts. Of course, we’re glossing over a lot here for the sake of brevity; check out our full article if you’d like to learn more.
Analytics Engineers: The new Role that owns the Modern Data Stack
4. Who and What the Data Is for Often Remains Unanswered
Some organizations are guilty of building their data team without a clear vision. They’ll start hiring before answering the question, “Who is this data for and what is that person supposed to do with it?” Attempts to answer this question have huge implications for your data team and what it does.
No One Knows Who the “Client” Is
Let’s start with the first part of the question—“who is this data for?” Often, the debate around this question boils down to two approaches to data team structure: centralized vs. decentralized.
A centralized data team is a single unit within an organization that takes care of all things data. It’s one distinct data team, separate from all other teams. With a centralized approach, the company’s data is for the data team to use or make usable for others. It’s data for those who know how to use it.
A decentralized data team is a cross-organizational group of data professionals, many of whom are embedded within the team they serve. There’s often a central team focused on data infrastructure, with specialized analysts and scientists embedded within other departments (e.g., a marketing data analyst who is a full member of the marketing team). With a decentralized approach, the company’s data is for everyone to use, and this access is facilitated by a close team member.
It’s rare for a data team to be fully centralized or decentralized. Most teams will fall somewhere on a spectrum between the two approaches. As a result, who the data is for will remain ambiguous.
No One Knows What This Data Is For
The purpose data serves within your organization will control what your data team prioritizes. And, as with the answer to who the data is for, this purpose is becoming more and more ambiguous.
Justin Gage, author of Technically and growth marketer at Retool, explains the two major approaches as Data as a Product (DaaP) and Data as a Service (DaaS). DaaP is where the data flows from the data team members to the rest of the organization as a packaged product. It’s a one-direction flow from the data experts to the masses. It’s data designed for use.
DaaS is where data is treated as a collaborative service, allowing outside stakeholders significant say in how data gets prepared and used. It’s a bi-directional flow where data is sent to the stakeholder, with feedback being sent back for the data team to iterate on. It’s data designed for collaboration.
But again, it’s best to think of these two approaches as two ends of a spectrum. Most teams will fall somewhere on this spectrum and even move from one end to another, depending on their immediate circumstances. Perhaps instead of DaaP vs. DaaS, just focus on what the business needs right now.
The Overall Upshot: There Is No Easy Answer

The purpose of a data team will continue to shift and change. What your data team needs is an easily adaptable data stack to help them navigate these changes with grace.
And we now have an idea of what this kind of data stack looks like. Jamie Quint, the previous head of growth at Notion, laid it out not too long ago:
Looks pretty similar to the Drizly stack we outlined at the start, doesn’t it? That’s because a new formula for data stacks is starting to shake out. It looks something like this:
- Fivetran to ingest data with no custom coding third-party integrations
- Snowflake to store structured and semi-structured data
- dbt to transform that data with a consistent, central library of modeling logic
- A BI layer for business uses (like Mode, Metabase, etc.)
- Census (of course) to send transformed data back to source tools like Salesforce
This rough outline of a data stack is a blueprint for a resilient, adaptable data infrastructure that can fit centralized teams, decentralized teams, small teams, large teams, DaaP-focused teams, DaaS-focused teams, and every team in between.
Want to learn more?
We help a lot of businesses think through the implementation of just such a data stack. If you’d like to discuss, request a demo and we’ll help you think through your options.