

































Ever tried to drive a nail with the handle of a screwdriver? Sure, you can do it. But a hammer delivers a faster, better result because it’s the right tool for the task. 🔨
The same thing is happening with iPaaS tools. Operational leaders at growing companies are struggling with large-scale data integration because they’re using a tool that wasn’t designed for the job.
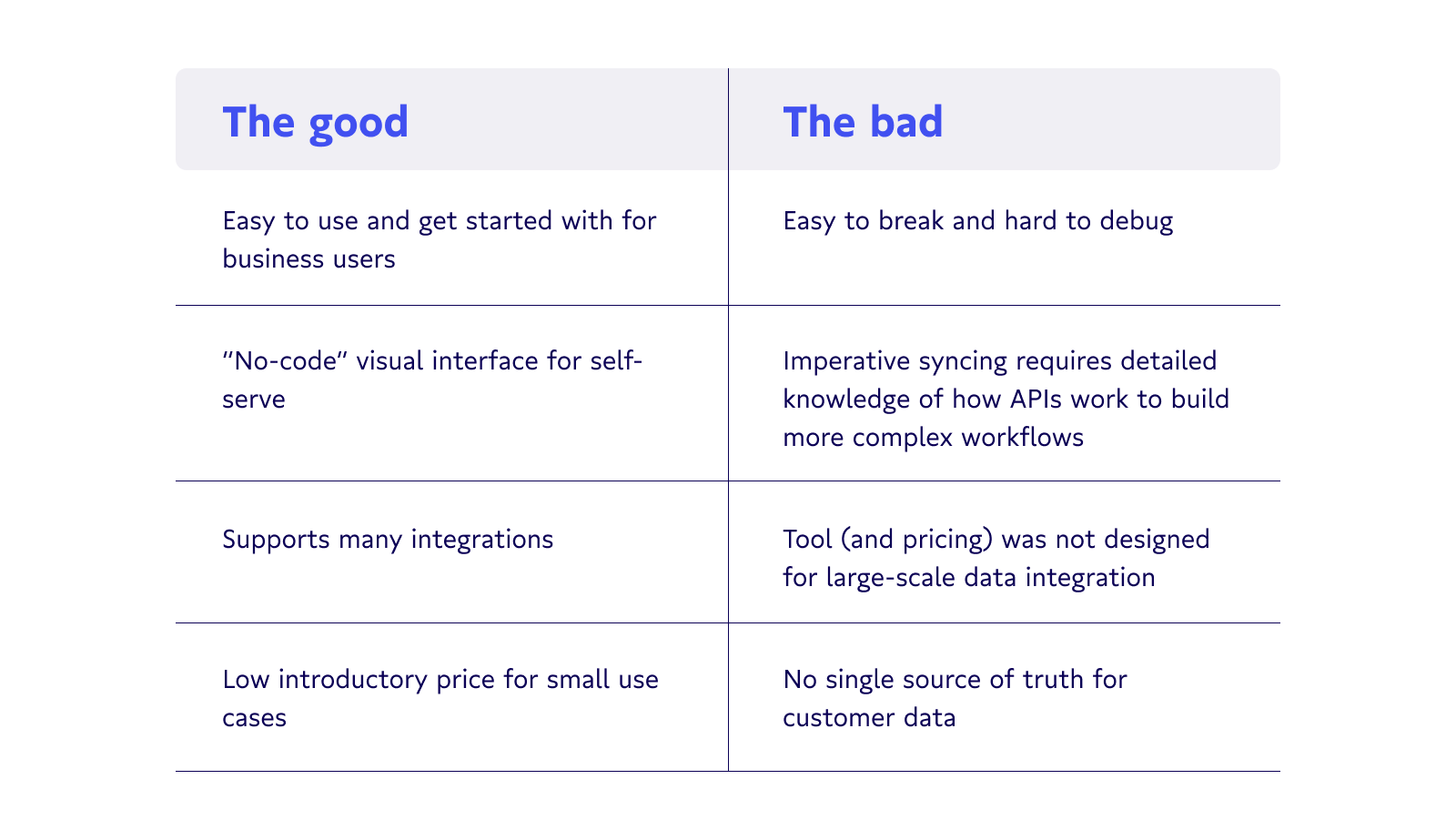
Easy-to-use iPaaS tools have a low entry barrier, making them a common starting point for early-stage businesses needing a few basic platform connections. But as the business grows and the number of integrations multiplies, teams can quickly lose control. Often they don’t even realize they’ve outgrown the system they rely on – resulting in messy data they can’t trust and a ticking time bomb to a data catastrophe.
Does that sound too dramatic? It’s not. Here’s a quick summary of why iPaaS tools don’t scale but read on to find out more. 👀
What is iPaaS?
An iPaaS, or integration Platform as a Service, is a platform that connects software applications so that specific activity in one tool triggers a specific response in a different tool. For example, a customer completing a transaction in Stripe could trigger the creation of a new customer profile in Salesforce. Another example might be adding a new employee to the payroll and automatically creating an account for them in the benefits portal.

iPaaS tools like Zapier, Workato, Tray, and Boomi use a no-code visual interface, eliminating the barrier to entry for non-technical employees. This makes them a great solution for business units like marketing, which may not have coding experience on the team but still need to maintain records across platforms.
Why iPaaS is the wrong tool for managing data at scale
Ultimately, iPaaS was designed to streamline workflows and eliminate the need for repetitive data entry. And it’s very good at those things. But problems arise when people emboldened by its user-friendly, no-code interface start applying iPaaS to use cases far outside what it was intended for.
Sure, it might seem to work for a while, but eventually, the tool starts to crack under the strain of doing work it’s not designed to do. When you use it to manage data movement at scale, iPaaS:
- Starts to break
- Requires an increasing amount of custom code
- Has a negative impact on data quality
iPaaS is easy to use, but also easy to break
One of the biggest reasons people love iPaaS is that it’s easy to use. In fact, it might actually be too easy to use.
(Ironic, isn’t it?)
Fundamentally, iPaaS connects a field in one system to a field in another system – which is great if you’re talking about a simple point-to-point integration with no dependencies. But because integrations are so easy to build, they can quickly multiply out of control, impacting downstream users and obscuring the single source of truth. 😶🌫️

iPaaS tools lack visibility, so as your company scales, you have more and more people creating more and more dependencies with zero ability to see how their workflows connect.
Say, for instance, a user splits a “full name” field in Salesforce to “first name” and “last name” so customers are easier to sort. They don’t realize another user created a rule in Workato that says not to email records if the “full name” field is empty. Suddenly, a huge segment of the customer base stops getting sales emails without anyone knowing there’s a problem.
When your company is small, you can avoid silos like this because everyone can talk to one another. But as the company grows, your point-to-point connections increase exponentially, and pretty soon you have a data integration spaghetti stack. Imagine, just 8 apps means 64 potential integrations. 🤯 And when one of those integrations breaks, good luck debugging it.
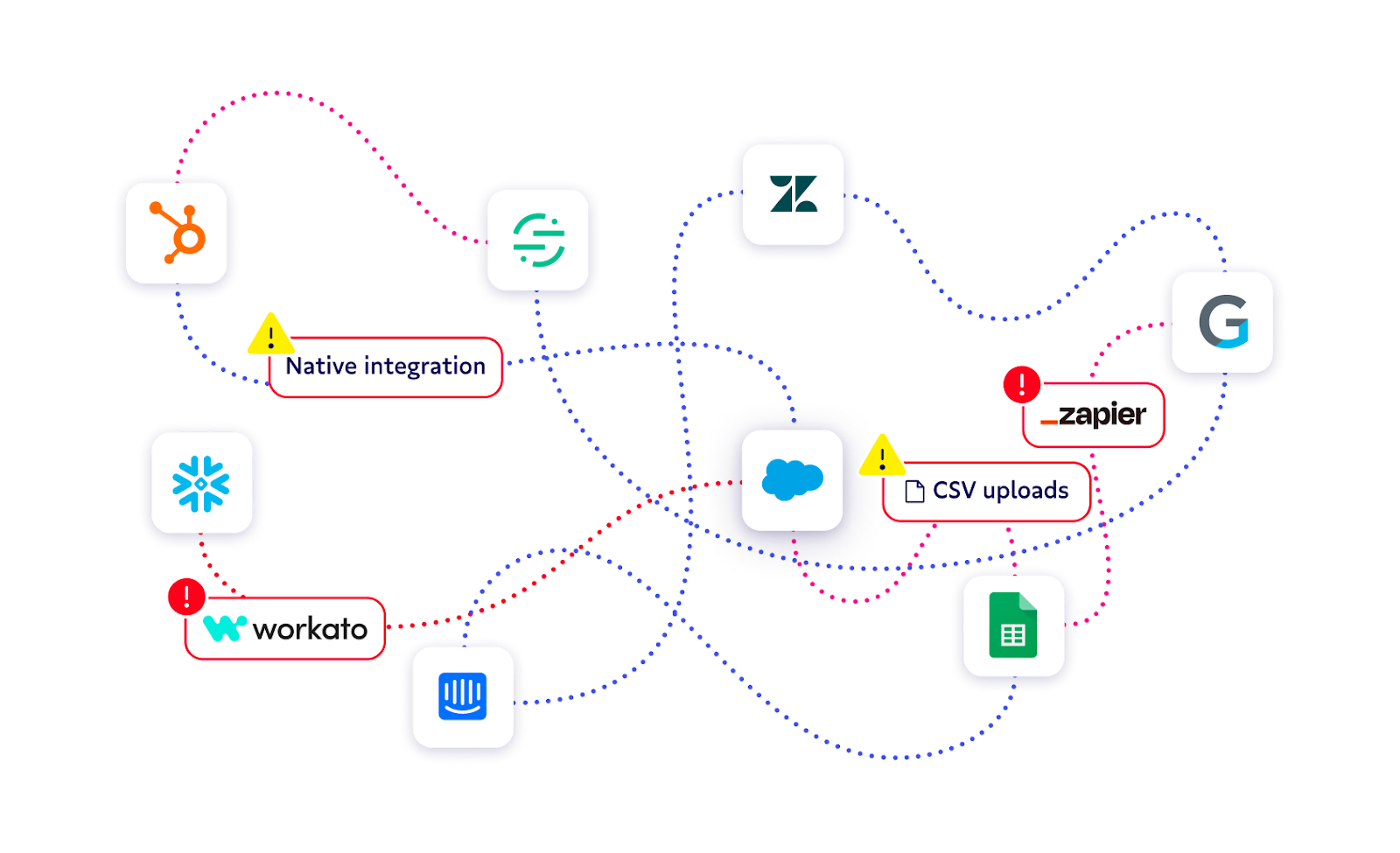
iPaaS can’t scale without chaotic custom code
The most appealing feature of iPaaS is its ability to connect applications via APIs that don’t require the user to have developer-level coding ability. But as workflows grow more complex you quickly realize users still need to have detailed knowledge of how APIs work – which defeats the purpose of a “no-code” tool.
This is because iPaaS tools work through imperative syncing, which means they’re really good at following directions, but you have to clearly map out every single step you want the tool to take. Often these steps require you to have detailed knowledge of how APIs and coding concepts like loops, lists, if/else work, etc. The only difference is you’re doing this visually instead of in actual code.
Let’s take a real example: Say you want to create a new deal in Hubspot if a record matches some criteria from a table in Snowflake. That sounds easy enough right? Wrong.
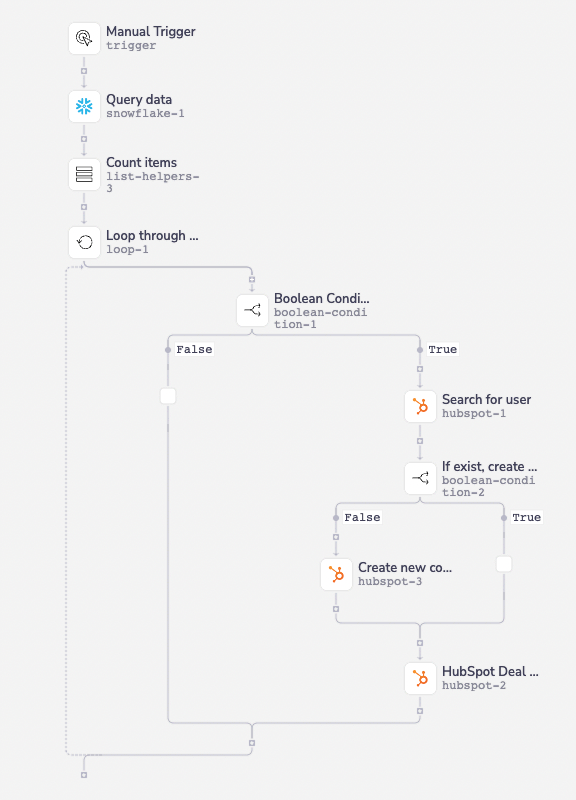
In trying to create this workflow you’ll hit several “gotchas” in understanding both how Tray works as well as how the Hubspot API works, like knowing that you first need to create a list of all the Snowflake records that match your criteria, then add a loop to go through each individual record in that list to check if the contact already exists in HubSpot. With Tray, you also need to enter required HubSpot deal properties like Deal Stage, or else your workflow ends in an error.
At this point, your workflow is only three steps in (and likely several hours of hairpulling if you had the same experience I did), and you haven’t even accomplished anything yet. 😑
iPaaS wasn’t designed for large-volume batch updates
Imperative syncing means iPaaS tools can’t deliver the end result you’re looking for unless you explain each step you want it to take. For simple point-to-point and IFTTT workflows – like the webinar registration I showed you above – it works great. But it was never intended to handle large-scale batch data updates – and its pricing structure reflects that.
Let’s take product usage data for instance. Knowing how individual customers use your product is vital to personalizing your marketing efforts to them. For example, our customer, Canva, has over 50 million users and wanted to send personalized email campaigns to them using Braze depending on which features they used the most. In order to do that they needed to update product usage data on each user profile inside Braze from their data warehouse. Since most iPaaS tools charge per API run, with Canva’s 50 million users this would get VERY expensive, very quickly. 💰
Read more on Canva’s data integration story here.
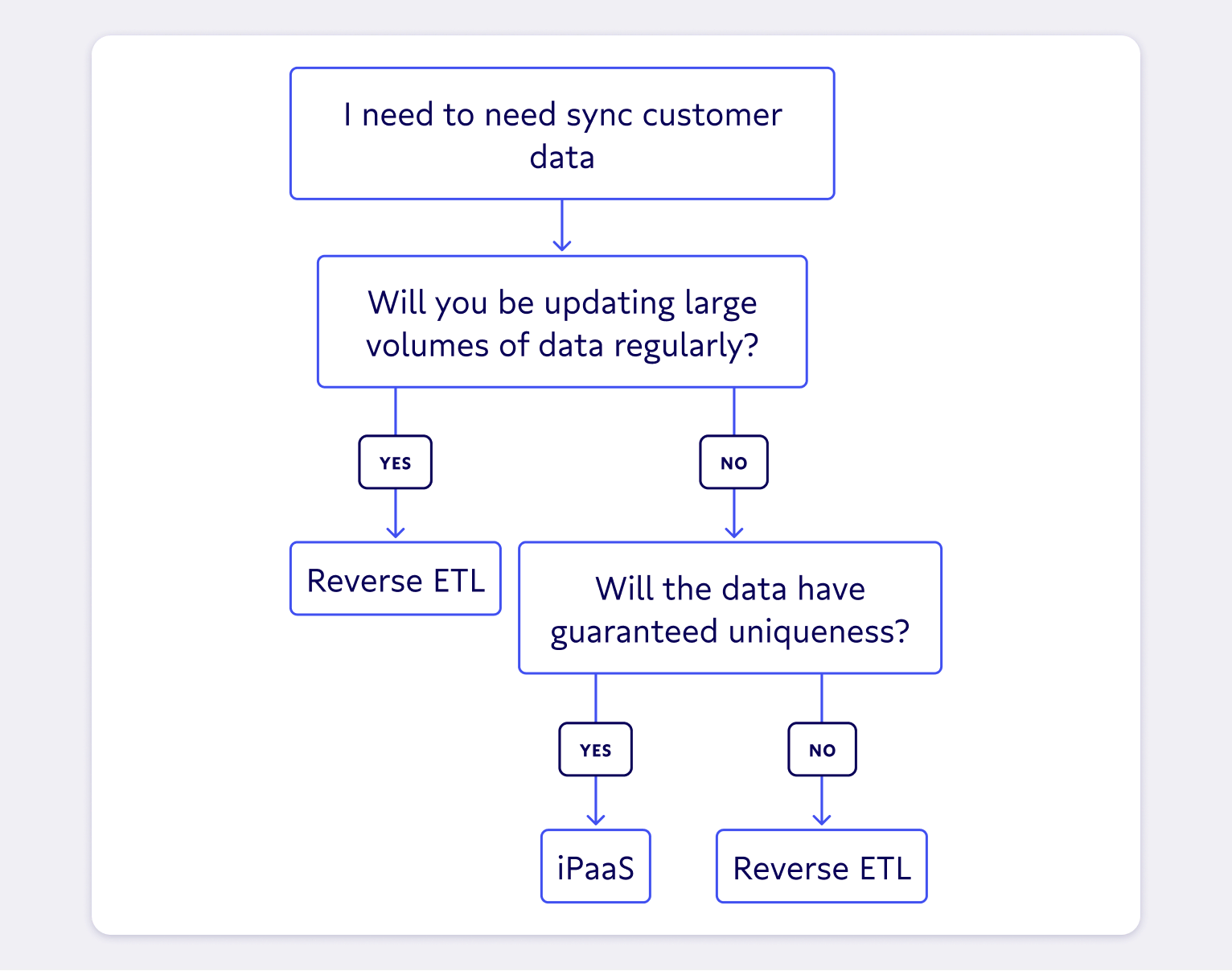
That’s not to say there aren’t some situations where iPaaS makes sense. Transactions with guaranteed uniqueness, like new employee onboarding, and simple IFTTT workflows are where tools like Zapier and Tray can shine.
But it was clearly never intended to handle large-scale batch data updates (and the pricing structure reflects that).
iPaaS complicates data governance and quality
Easy integrations and zero visibility – that’s a one-two punch for data privacy concerns. 👊
When people without a proper understanding of data can easily send it between systems, high-security data can accidentally get jumbled in with low-security data. That means that information that should be protected can leak into applications where it doesn’t belong.
The lack of visibility also means a lack of data lineage. iPaaS solutions have no historical record of data versioning which makes it impossible to reconcile old and new data sets. Breakdowns and errors in the pipeline are a nightmare for the data team to find and fix. 😱
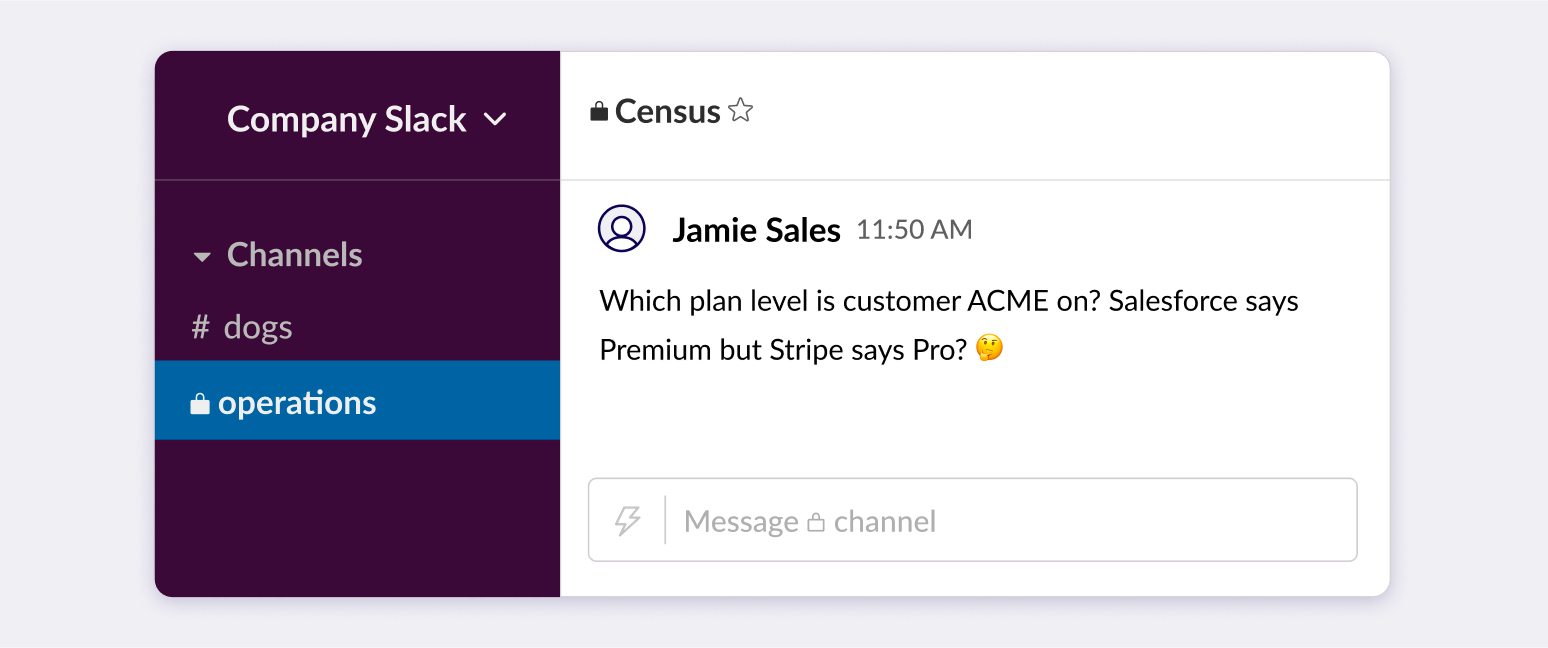
Reverse ETL is a better way to sync data
When bad data triggers the wrong automation or leads executives to the wrong decision, the results can range from mildly embarrassing to completely devastating (like sending the wrong emails to thousands of customers). Most companies today already centralize their data in a “single source of truth” AKA a data warehouse for business intelligence purposes.
Reverse ETL takes that one step further by delivering customer data from your warehouse (your source of truth) right to the tools your frontline business teams use. It enables data teams to maintain high-quality data models in the warehouse, and have business teams sync trustworthy data from those models into their business applications in a self-serve way.
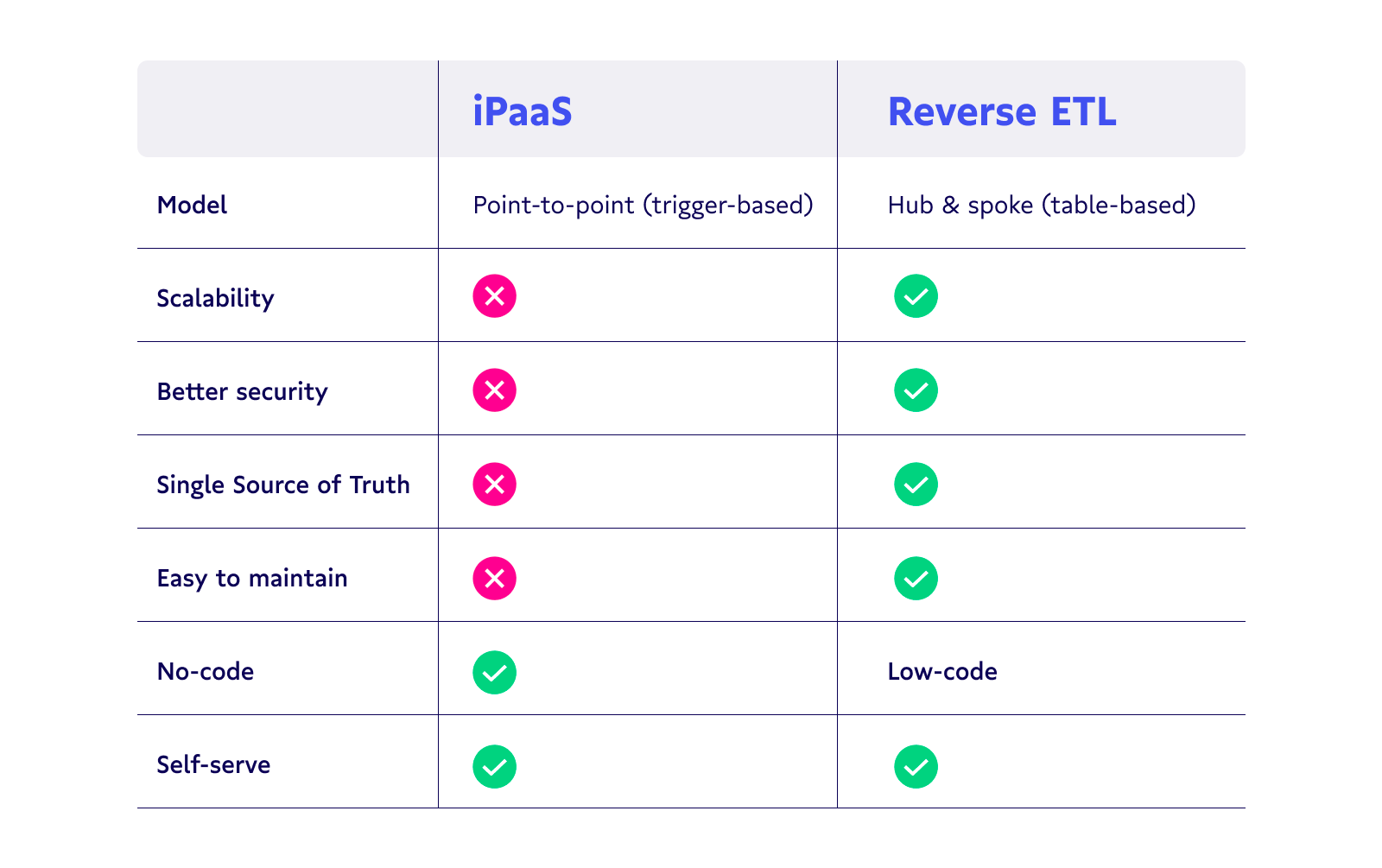
Reverse ETL relies on a single source of truth – the data warehouse
iPaaS moves data linearly from Point A to Point B. For one-off scenarios like syncing a single record, a linear model is great. When a trigger happens at Point A, this data moves to Point B. Simple.
The problem arises when you’re trying to manage reliable data in a number of workflows and applications. Every team sees just a piece of the truth; no one has a complete, 360-degree view of the customer. This leads to silos, inconsistent customer experiences, and decisions made without crucial information.
Reverse ETL uses a hub-and-spoke model where your data warehouse sits at the central hub, providing a single source of truth to all the workflows, systems, and applications radiating from it.
Reverse ETL uses batch-based transformations
One reason iPaaS transformations aren’t scalable is that records move through the system one at a time, repeating the trigger for each new record. When you need to transform thousands of records, the trigger-based method takes a looong time. 😴
If a transaction fails, the tool will try several more times before giving up, bottlenecking the system. There’s no historical record of transformation versions, so you probably won’t realize that record is out of sync, becoming staler and staler the older it gets.
On the other hand, Reverse ETL performs batch transformations at the table level. This is faster, cheaper, and more reliable than looking at records one at a time. If a transaction fails, you won’t end up with a stale record – at the next sync, the system will check against the data warehouse and bring any changes up to date.
Continuous syncing means the system can update in near real-time. Your Reverse ETL tool will intelligently diff data between syncs, so rather than sending all the data every time, it checks the table’s current state against the last sync and only sends the fields that have changed.
Why declarative data syncing makes more sense than imperative syncing
Imperative data syncing requires you to give the integration tool detailed step-by-step instructions. When your integration is complex, declarative data syncing is much simpler. Instead of telling the tool each action you want it to take, just tell it what result you want it to achieve.
Now, let’s go back to that product usage data example. With an imperative model, we had to tell the tool to compare specific fields in Application A with specific fields in Application B, then tell it what to do if they matched and what to do if they didn’t.
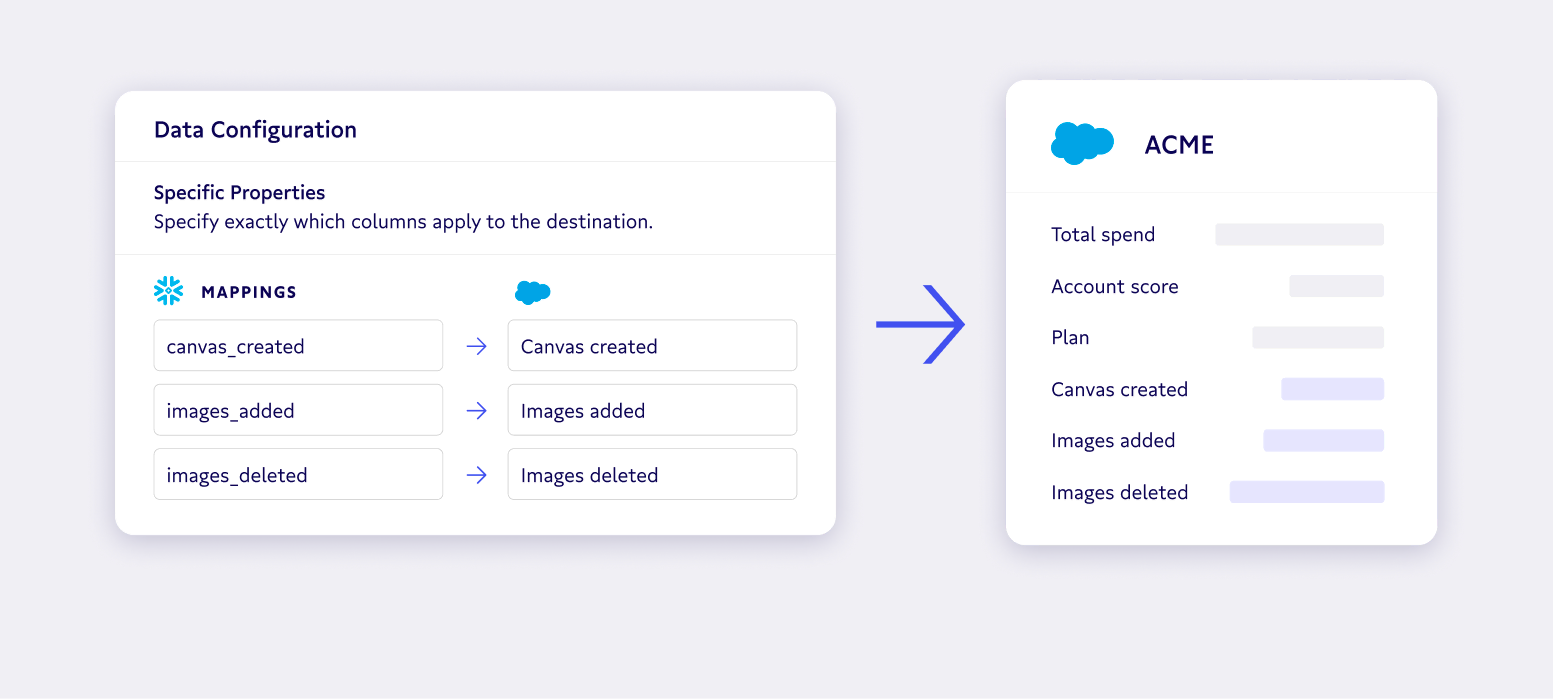
With a declarative model, we just tell a tool like Census to map data from the data warehouse – our single source of truth – to the destination field in our chosen application. We tell it how often to check for updates, then let it go while we turn our attention to more important things.
When should I move from iPaaS to reverse ETL?
When we’re talking about technology that scales, it can be helpful to plot your company on a maturity curve. The more you grow, the more mature your data systems need to be. 📈
Where do you fit today?
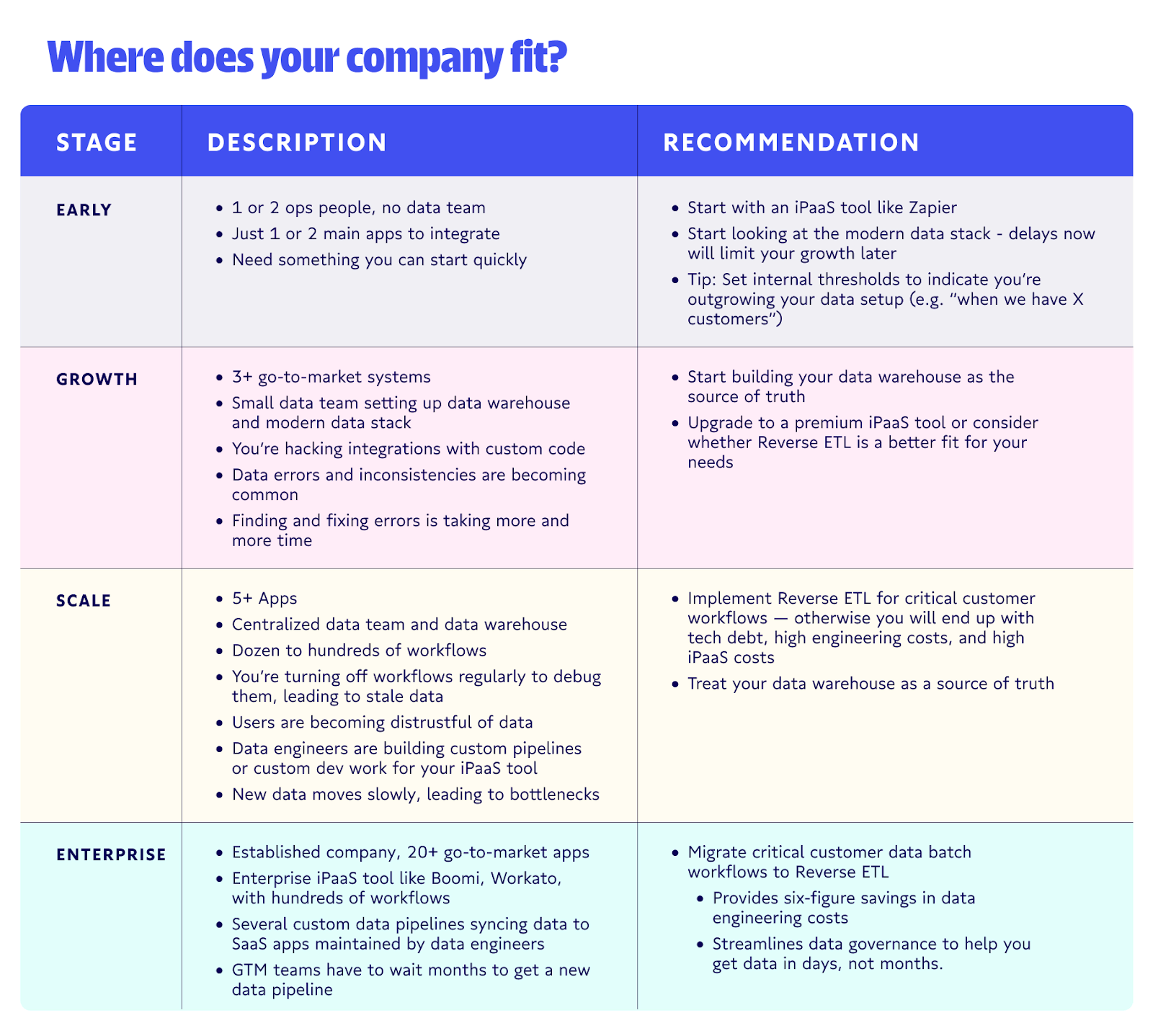
Ultimately at every stage, you need to be thinking about trustworthy data and team productivity. The bigger your organization gets, the more dependent it becomes on data – and the lower its tolerance for bad data. When you were small, a wrong automation or data error might impact 150 customers. Now, that automation might affect 50,000.
Visibility becomes critical once you can no longer afford unreliable data, so the longer you try to get by on a system you’ve outgrown, the more time your data team will spend tracking down and fixing errors and the longer data-driven decisions will be delayed.
iPaaS vs. Reverse ETL: Choosing the right tool for the job
You don’t have to choose between using iPaaS or using reverse ETL. You can use both. (We do.) Your toolbox can have both a screwdriver and a hammer. What matters is that you’re using the right tool for the right job. 🧰
The more data, systems, and people your company has, the more important it is to maintain visible pipelines inside and out of a single source of truth. If you’re already using business intelligence to inform important decisions, you need reverse ETL to make sure your Go-to-Market tools have the same fresh, reliable data.
Census syncs data from your warehouse into all your business tools without any messy point-to-point integration webs. Schedule a demo and see how it can help you scale your data operations to the next level. 📈