































Retailers’ Challenges - More Data, Less Humans
The retail and e-commerce industry is experiencing a data deluge during a resourcing drought. An enormous influx of customer, inventory, and other data types is pressuring businesses, primarily due to the industry's rapid digitization. This challenge is unsurprising as "non-store and online sales are expected to grow between 10% and 12% year over year to a range of $1.41 trillion to $1.43 trillion,” according to NRF’s 2023 forecast.
With today's technologies, companies can gain more insight into their customers and operations with every click, purchase, return, subscription and review. On the inventory front, teams deal with complex stock-keeping unit (SKU) data, multiple sales channels, and supply chains. Sorting through this can be tedious and result in inventory mismanagement, stock-outs, or overstocks. Furthermore, businesses are combing through other types of data, such as customer, financial, and marketing, each carrying critical decision-making and customer experience potential.
While this data may be advantageous to some brands, many growing companies face the challenges of standing up proper in-house pipelines and infrastructure in a scalable, real-time, cost-effective manner. There is not only significant investment needed from engineering and data teams to build, but the maintenance burden can be even more taxing over a longer time horizon. In a recent survey by Ably of over 500 engineering leaders, “70% of real-time experience infrastructure projects lasted more than three months, and over 90% of projects had 4+ engineers working on them.”
On top of the pressures of rapid digitization and data maneuverability, slowing market conditions and shrinking budgets have increased pressure on these brands to maintain operational efficiency. This trend often means reducing staff, limiting technology procurement, and curtailing data investments. This environment can lead to delayed or poor decision-making, impacting inventory management, customer relations, and overall sales.
For instance, inadequate customer data modeling could result in missed opportunities to personalize marketing efforts, reducing customer engagement and lowering conversion rates. Suppose a brand can't correctly identify your historical purchasing behavior across channels (in-store, app subscriptions, etc.). How can it properly communicate to you offers, new product releases, or other updates to maintain and grow brand loyalty?
The Modern Data Stack Solution
Unfortunately, this macro environment where data innovation and opportunity meet resourcing constraints keeps many business leaders up at night. “How can we do more with less?” is an all too familiar mantra for teams looking to meet lofty sales targets and goals. Luckily, a wave of technical innovation and operational efficiency is occurring around a disruptive technology - the cloud data warehouse.
The data warehouse is ideal for storing copious amounts of data, effortlessly conducting queries, and establishing connectivity across your company. In all likelihood, your organization already utilizes one, reducing the need to procure Customer Relationship Management tools (CRM), Data Management Platforms (DMP), or other tools that bloat your technical infrastructure. While experts debate the current state and future of the Modern Data Stack, the utility of composable architecture around a centralized hub is straightforward.
Positioning the cloud data warehouse as the central element of your Modern Data Stack (MDS) yields considerable advantages such as:
- Data Ownership: This arrangement bolsters your compliance with privacy stipulations and regulations.
- Quick Value Realization: Depositing historical data into a database is significantly more straightforward than integrating the data into an additional tool.
- Streamlined Synchronization: Databases are universally compatible, unlike SaaS tools, which may offer limited APIs.
- Reusability: Various teams within your organization can rely on this dependable information reservoir.
However, if you want to drive business outcomes from your warehouse truly, there are three critical layers of a Composable CDP for you to consider:
Data Collection Layer: Utilize Snowplow to collect real-time events on your website or application. In parallel, leverage an ETL platform such as Fivetran to load data from external platforms into your data warehouse properly.
Data Transformation Layer: dbt is the preeminent data modeling tool to transform your data warehouse into a model applicable to your business needs.
Data Activation Layer: Census seamlessly integrates with dbt, Snowplow, and Fivetran, thus enabling the synchronization of your data with all your business tools.
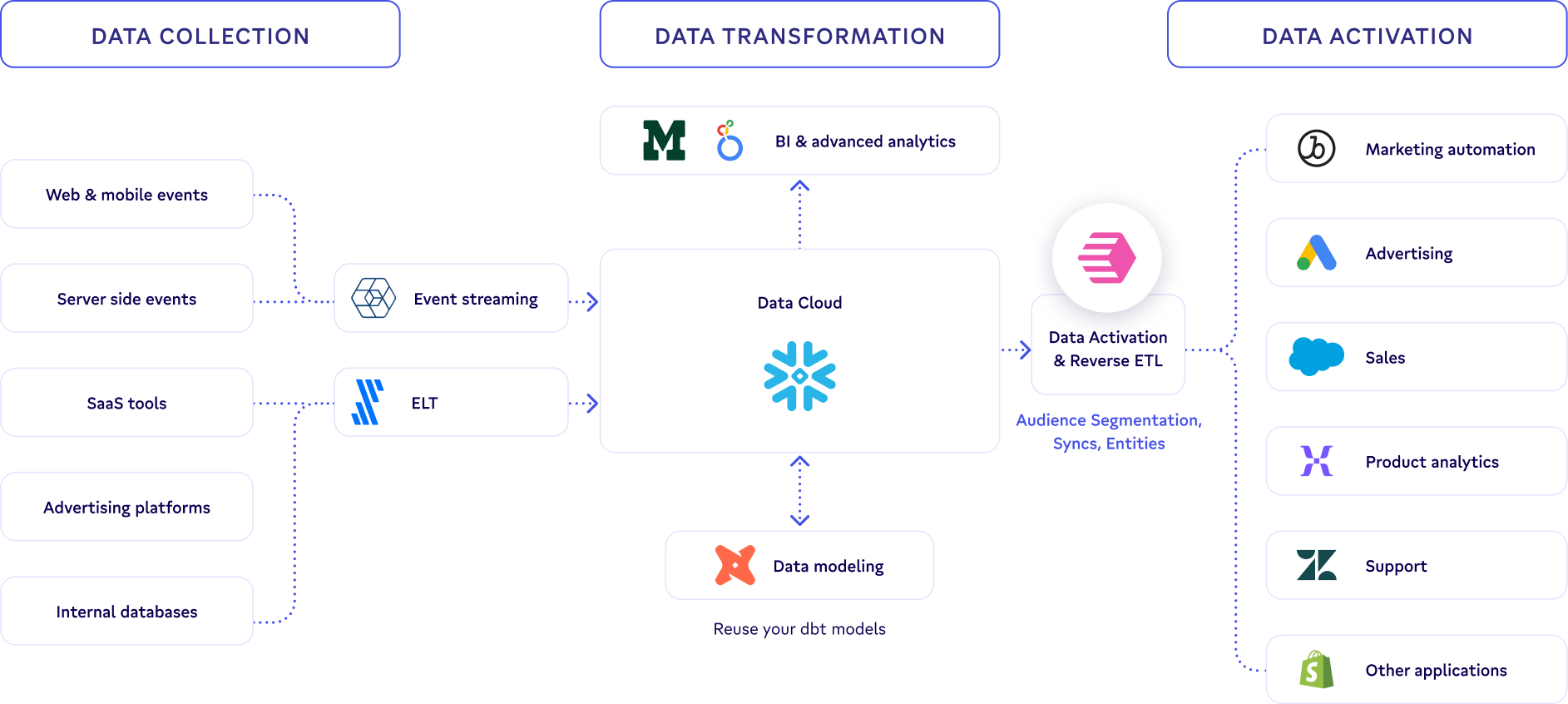
|
By implementing complementary, composable data platforms around your single source of truth, you can seamlessly collect, transform and activate data in a way that makes sense for your business. Despite this architecture's ease of integration and use, not all companies will have the internal bandwidth to tackle this evolution and must look outwards for help.
How businesses are adapting to the Modern Data Stack thanks to Hiflylabs
As mentioned earlier, the data deluge is just one of the hurdles facing retail teams. While the data warehouse and surrounding MDS components allow organizations to manage data complexity, a human element is still involved with this change management process. An NYC-based e-commerce company established in 2018 faced such challenges and looked externally for help in its organizational shift around the MDS.
Despite lacking an internal data team, the company aspired to be data-driven and enlisted Hiflylabs to assist in its data management and activation initiatives. Challenges ranged from inherited model errors and low-quality code from previous partners to a lack of documentation for essential metrics such as customer acquisition cost (CAC), annual recurring revenue (ARR), and lifetime value (LTV). They also faced issues with data synchronization between key commerce platforms such as WooCommerce and Recharge.
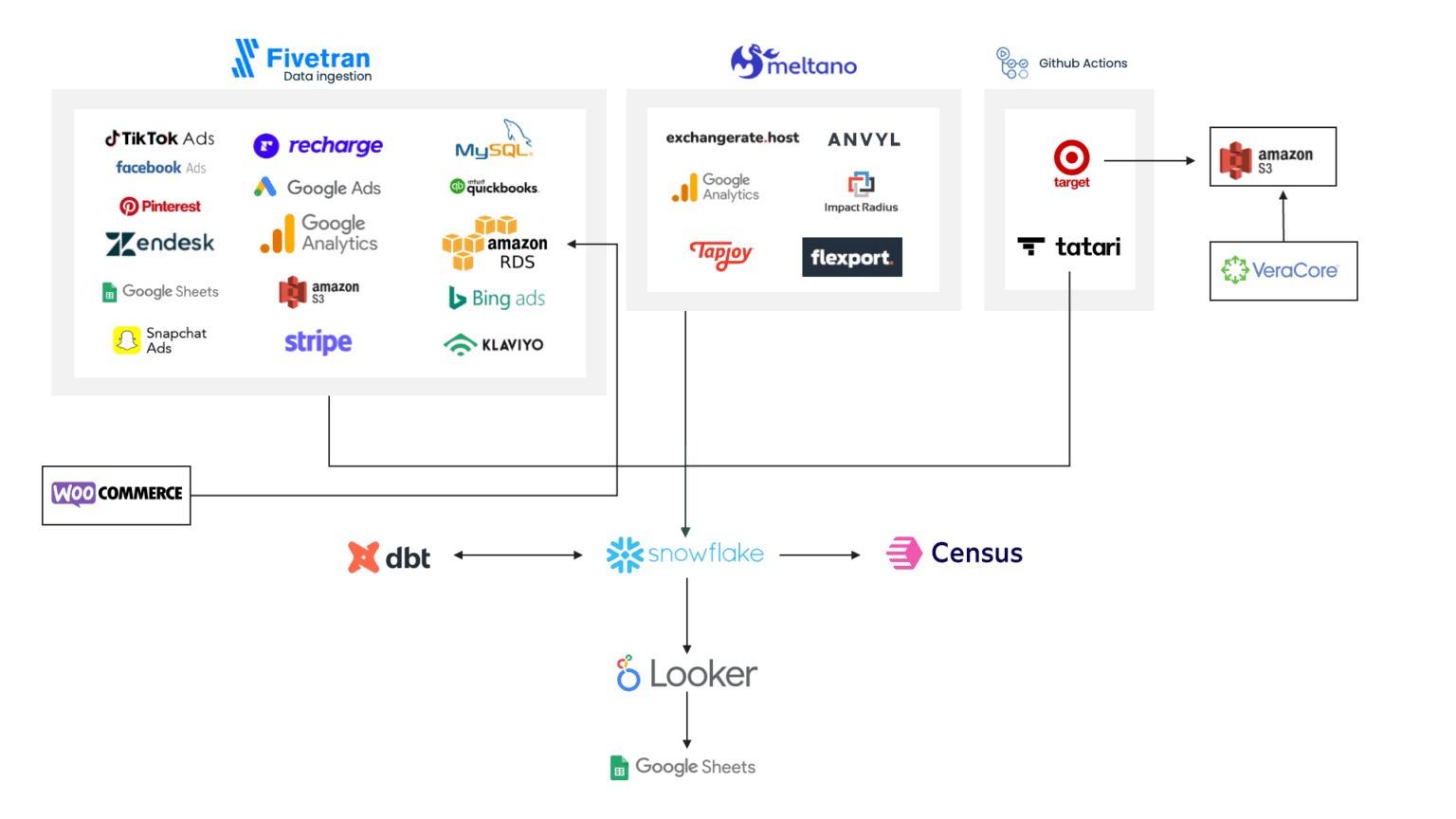
|
In response, Hiflylabs utilized the MDS to standardize development and deployment processes. They refined hundreds of models, conducted tests, and implemented macros to enhance data operations, redefining crucial metrics like customer cancellations, cohort analysis, churn, and retention calculations. This collaboration resulted in a modernized CI/CD pipeline, streamlined data management, and facilitated dashboard creation and reporting for non-technical stakeholders. Their successful partnership has paved the way for a stable data ecosystem for their teams to operate within, and a commitment from Hiflylabs to provide ongoing opportunities on the company's data journey.
While this architecture and operational overhaul was a priority for this particular brand, a crawl approach might appeal more to your company's situation. Hiflylabs' expertise in dbt and Census could be a great first place to start. Let’s look at how Census streamlines dbt modeling through its recently released packages and tackles some common identity modeling use cases.
Modern problems require modern packages
If the basic concepts of dbt (data build tool) didn’t catch your attention the first time, dbt macros will surely do. Macros allow you to add Pythonic functions to your SQL transformations. You can create your own macros with Jinja formatted SQL files, or if you are facing common issues, you can easily pick one from the shelf among the several dbt packages.
How do dbt packages work? You simply just add the selected version to your requirements.txt in your dbt project folder. Run a few commands, and all the macros are available from the given provider. Not all packages are equally valuable, and for Hiflylabs, a few “must-have” packages can be used for everyday development. A great example is the dbt_utils package, which the census_utils builds upon.
The census_utils dbt package is a practical solution for some customer identity challenges
The census_utils package includes six simple but super-handy macros:
- parse_ga4_client_id (source)
- clean (source)
- is_internal (source)
- extract_email_domain (source)
- is_personal_email (source)
- get_country_code (source)
With the is_internal() and is_personal_email() macros, you can solve some fundamental problems distinguishing internal and personal email domains.
Meanwhile, this package can also extract commonly used data parts with the extract_email_domain() and get_country_code() macros.
The cherry on top is the simple but super-handy data transformation capabilities with the clean() and parse_ga4_client_id() functions. These parse your data into a neat format, and you can load it directly to the Facebook or Google Ads APIs.
Closing Thoughts
In the grand theater of digital transformation, the Modern Data Stack has become the star performer. It's a riveting act, juggling scalability and real-time processing, transforming mundane data into insightful narratives and illuminating the path to customer engagement, operational efficiency, and decision accuracy.
Sometimes it takes a skilled choreographer like Hiflylabs to guide the dance, ensuring every step is in sync with the rhythm of business goals. So, as the retail sector takes the stage in the age of information, it's clear that mastering the dance with data determines who gets the standing ovation.
Interested in how Hiflylabs and the Modern Data Stack can benefit your business? Want more information about how Census's dbt packages can address your data modeling concerns? Contact Hiflylabs for a free consultation or book a demo with a Census product specialist!