































This is part 3.1 of our series on evaluating reverse ETL tools. This was updated December 14, 2022 to better capture current reverse ETL considerations. You can read part one here and part two here, or grab a copy of the companion guide, The ultimate guide for evaluating reverse ETL tools.
In this installment, you’ll learn the difference between bundled and dedicated reverse ETL tools. Once you've decided which lane of reverse ETL software you're after, we'll provide you with four key things you should consider as you evaluate your reverse ETL vendor, including:
- Data connector quality ⭐
- Sync robustness 💪
- Observability 👓
- Security & regulatory compliance 🔒
We’re assuming (since you’re reading this) that you’ve come across at least some material on reverse ETL. You’ve probably heard about how it can drive personalization and growth at a completely new scale, unblock data teams to do their best work, and unlock operational analytics.
Good news: It’s all true. Challenging news: There’s a lot to consider when you’re choosing your reverse ETL vendor. That’s why we designed this guide to help data and ops leaders understand the key things to look for when partnering with a reverse ETL vendor.

Each reverse ETL tool on the market is unique, and not all are created equal. Before we get too deep into the considerations to keep in mind, you should know that there are generally two lanes of reverse ETL software on the market today:
- Bundled reverse ETL tools from companies that offer reverse ETL functionality as part of their larger suite of services. This may sound like a good deal (especially if you’re already using the overall suite), but as we talked about, reverse ETL isn’t just another pipeline or feature set. Providers that bundle reverse ETL into their main offering often don’t include the same or as many integrations as dedicated platforms. In the same way that you wouldn’t want your friendly, neighborhood general practitioner doing your emergency heart surgery, you want precise expertise when it comes to the tools that operate at the heart of your business (your data).
- Dedicated reverse ETL tools (that’s us 😄). There’s an increasing number of companies singularly focused on building the best reverse ETL tool they can. As the pioneer of the category and operational analytics, we believe that this route toward specialized tools is the correct choice for most companies out there.
If you’re ready to start the journey toward doing more with your data (and time), here are the eight key consideration areas you should keep in mind when evaluating tools.
Regardless of which lane of reverse ETL tools you decide to go with, you can use the following consideration areas to make sure you choose the option that best fits your use case. These considerations break down into:
- Data connector quality
- Sync robustness
- Observability
- Security & regulatory compliance
1. Data connector quality ⭐
Reverse ETL tools are only as good as the quality of their connectors. These tools pull your data from the source and SQL models and push it into your business apps like HubSpot, Salesforce, Marketo, Braze, and Netsuite via native APIs.
We break down data connector considerations into two categories:
1. Connector breadth (features that span all connectors)
2. Connector depth (the features dedicated to the individual connectors you need)
Here’s what you should keep an eye out for within each connector lane.
Connector Breadth: High-level data connector considerations
When looking at connector breadth for your potential reverse ETL vendor, there are four tenets of quality to look for:
1. Your vendor offers the high-quality connectors you need today. It should integrate with the business tools (both sources and destinations) your organization needs today. Keep in mind that no tool offers integration with every CRM or app out there. Prioritize vendors with a reputation for high-quality connectors, and beware of platforms that boast high-velocity, underdeveloped data integrations.
2. Extensibility is a priority for your vendor. Extensibility ensures that if you need a custom integration for a specific purpose, your vendor can support it well. This generally comes from a Webhook or custom API connector which can handle the last mile of integration with native APIs so you can quickly hook up a tool and enjoy sync robustness all the while.
3. Specialized connectors vs add-on connectors. Existing ETL or DataOps vendors may offer limited reverse ETL capabilities, but this often means connectors aren’t given the full attention and time they need to stay up to date (which means more troubleshooting for your team).
4. Whether it’s an open-source or managed reverse ETL tool. While open-source tooling offers extra flexibility, the current OSS reverse ETL connectors only support a fraction of the integrations of managed tools. If you’re concerned about getting locked into a proprietary tool, compare connector extensibility over whether or not the tool is open source.
At the end of the day, it doesn’t matter if a vendor offers a large number of half-baked integrations that you either A) don’t use or B) can’t rely on. Checking for these features when evaluating the best reverse ETL solution for your use case ensures that you can trust your tooling as much as you trust your data.
Connector depth: Individual connector considerations
While it’s important to make sure your vendor’s reverse ETL software offers a wide range of connector options for your current and future use cases, you also need to do your due diligence to make sure they offer the depth you need to deliver data where — and how — you need it.
Just as there were four tenets of connector breadth, there are two tenets of connector depth to measure your reverse ETL vendor options:
1. The vendor offers support for all the objects you need for each key connector. Unlike the ETL tools you may have used in the past, there are structural nuances to consider when syncing data back into business systems since each business app has its own data structure. This means no standards exist between connectors, and multiple objects have different rules between them.
2. The tool helps you simplify these complex object syncs and relationship mapping. You shouldn’t have to spend hours architecting mapping to make sure syncs go through. Instead, your vendor automatically handles multi-object syncs and alerts you when an issue arises so you can quickly resolve it.
2. Sync robustness 💪
Syncs define the rules and manage the workflow around how your data is sent from your single source of truth (AKA your data warehouse) or another source to your destination tools. You likely have multiple syncs pulling from the same data connector for different SQL models and use cases. This means sync reliability is, arguably, the most critical part of your reverse ETL tool.
When choosing a vendor, you should consider the following six sync characteristics across all syncs, regardless of connectors:
- Sync reliability or Just Works™. This sounds simple, but the advantage of sync reliability can’t be overstated. You need to know that no matter what happens in your data pipeline (rate limits, network issues, etc.) your data will eventually sync, without duplication or loss (or, as Fivetran calls it, idempotence). Your reverse ETL platform should seamlessly retry syncs if they fail, intelligently handle changes to data models, and alert you to issues, unlike most point-to-point systems.
- Data validation. Your business apps are only as useful as your data is trustworthy. Your reverse ETL vendor should offer automatic deduping capabilities as a line of defense against bad data quality. This is particularly important as your business teams become more self-service and sync data to Google Ads or Facebook Ads where dupes cost you cold, hard cash.
- Incremental syncs. Your tool should only sync the data that’s changed, rather than all existing data in a “full sync." Incremental syncs, combined with batch APIs, ensure you steer clear of API rate limits and don’t rack up high API bills from your apps.
- Automated sync scheduling. We fundamentally believe that no one should spend their time stressing over sync schedules. You should just be able to set your syncs, know they work, and get on with your data-driven life. As such, make sure your vendor supports sync scheduling automatically on a schedule of your choice, from weekly to continuous syncs.
- Triggering sync scheduling. In addition to an automated sync scheduling feature, your vendor should support trigger sync via your orchestration layer (Airflow), your models (dbt), and programmatically via API.
- Sync speed. Nothing is more annoying than waiting for data you know is in your cloud data warehouse, but not yet available in your tools. Make sure that your vendor offers reasonable sync speeds based on your largest volumes of data that satisfy your freshness demands, particularly for large volumes of data or data that fuels real-time analytics.
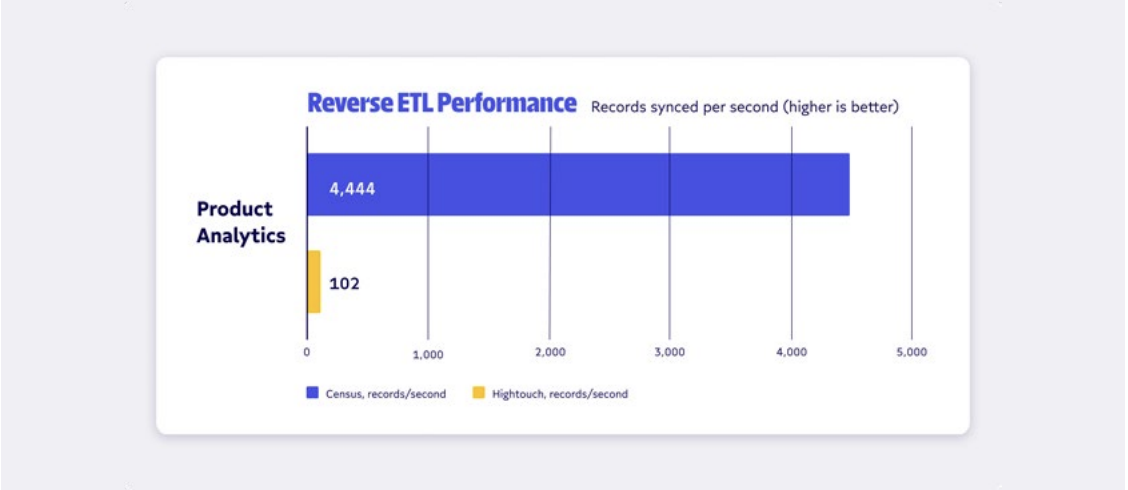

3. Observability 👓
Try as we (and any other company might) there are just some times that the data Just (doesn’t) Work™. In the event of this, your reverse ETL vendor should alert you quickly, and help you understand what’s gone wrong and how to fix it. Ideally, they should help you stay ahead of data surprises with warehouse-centric observability so your data teams can sync data into downstream business tools with confidence (and without all the bug smashing).
To confidently help you fix data issues, this means the best reverse ETL tools must offer the following five observability features.
1. Alerting. Your reverse ETL tool shouldn’t just limit alerts for failures. It should include them for invalid and rejected records as well as general error messages to help you take proactive action to fix issues before they cause major breaks. These alerts should be available quickly via email and Slack when something goes wrong.
2. Integration with your favorite monitoring tools. Your reverse ETL vendor should meet your stack where it is, and this includes easily integrating with your favorite monitoring tools (e.g., Opsgenie, PagerDuty, Datadog, or even Slack). This could be via a native integration, or through other levers such as webhooks and ensuring logs can be parsed by those systems.
3. Detailed logging. You should be able to easily reference and understand what records failed and why, as well as which were successfully synced so you can feel confident your data has synced correctly or quickly troubleshoot any issues you’re alerted to. Logs should be compatible with SQL so you can query them with the tools you already have, including BI tools, SQL clients, and data testing frameworks like Great Expectations or dbt. These should live in your data warehouse for easy analysis.
4. Usage audit logs. You should be able to track all usage of your reverse ETL tool from the business user level and understand exactly who’s made any changes to models or sync configurations and when. This includes any changes made by vendor support teams.
5. Real-time debugging. You should be able to easily debug in real-time if something goes wrong with visibility into API calls at the row level. That way, your data team can monitor and debug any problematic syncs, and get ahead of data issues proactively. Plus, you can ensure the consistency, reliability, and observability of the data you’re sending to your destinations.
It may seem like the work your data engineers do is magic, but the reverse ETL layer of your pipelines shouldn’t be a black box of mystery. Instead, you should be able to see what the tool is doing, which data it’s accessing, and where that data goes. No white rabbits or magic wands required.

4. Security & regulatory compliance 🔒
Your customers (and regulators) expect your company to act as a good steward of the data you collect. As such, your reverse ETL should be a security and compliance asset, not another liability. When it comes to moving the sensitive personally identifiable information (PII) of your customers between systems within your company, this really isn’t a time to cut corners.
When evaluating a reverse ETL vendor there are five key considerations to keep in mind:
1. Your tool should let you own your own data. Any good reverse ETL tool should seek to minimize both the number of places and the amount of time your customer data is stored. This means:
a. Your vendor should minimize data retention so they don’t store your data for a moment longer than needed to sync it to the destination.
b. Your vendor should ensure data stays in your environment. In order to only perform incremental syncs, it’s common for reverse ETL tools to store a snapshot of your data, so each sync can create a ‘diff’ between data states. Your tool should seek to minimize the number of systems it stores that data in, and, ideally, store snapshots in the same place as the data source. Additionally, your vendor should limit the number of systems your data moves through.
2. Your vendor should meet progressive regulatory standards. As a baseline, your vendors should be SOC 2 Type 1 and a best-option will also sport SOC 2 Type 2 regulatory compliance to reflect deeper security maturity and investment. Beyond this, it’s important to make sure your vendor meets industry-specific standards that apply to your organization, such as the Health Insurance Portability and Accountability Act (HIPAA) or the Payment Card Industry Data Security Standard (PCI-DSS).
3. Your vendor should encrypt data at rest and in transit. This should be covered by SOC 2 compliance, but double-check your vendor offers data encryption both when information is at rest and in transit.
4. Your vendor should leverage the best security available for API connectors. Check to make sure your vendor requests as few OAuth scopes as possible for SaaS applications (subject to SaaS provider support, of course). This also means your vendor should take an active role in staying up to date with the emerging security capabilities of business tool APIs (e.g., mirroring the support for hashed data currently offered by Google Ads and Facebook Ads).
5. Your vendor should have a governance plan. To ensure that you (and the rest of your org) can trust your data, your vendor should know where your data is, how it's being utilized, and whether or not it's adequately protected, including access controls and model validation by data teams. It’s not enough that your data be correct. It needs to be secure and safe, too.
The best reverse ETL tools check all the above security boxes to ensure this trust today and into the future.
Ready to learn more? Check our final part of the series on evaluating reverse ETL vendors: 4 (more) key considerations for finding the best reverse ETL tool where we'll dive into requirements for ease of use, community and vendor support, and pricing. Or, if you’re ready to start shopping around, grab The definitive guide to evaluating reverse ETL tools.