































Want to learn why customers chose Census over Hightouch? Check out the comparison page.
From the beginning, we designed and built Census not just around reliability and usability, but the ability to deliver high performance on workloads large or small. But it’s not enough to just build with those tenants in mind. We’ve dedicated ourselves to measuring and examining where our efforts have paid off, as well as where we can double down to raise the standard higher.
Today we’re excited to kick off a series of posts benchmarking popular reverse ETL tools to both hold ourselves accountable to our high standards and provide the market with a breakdown of their options.
We’re starting with large-scale event sync workflows, arguably where speed and scale matter the most.
We’ll get into the details in the following sections (and installments), but, in our initial testing, we found Census was up to 44 times faster than Hightouch when measuring end-to-end sync speed for Mixpanel events syncs.
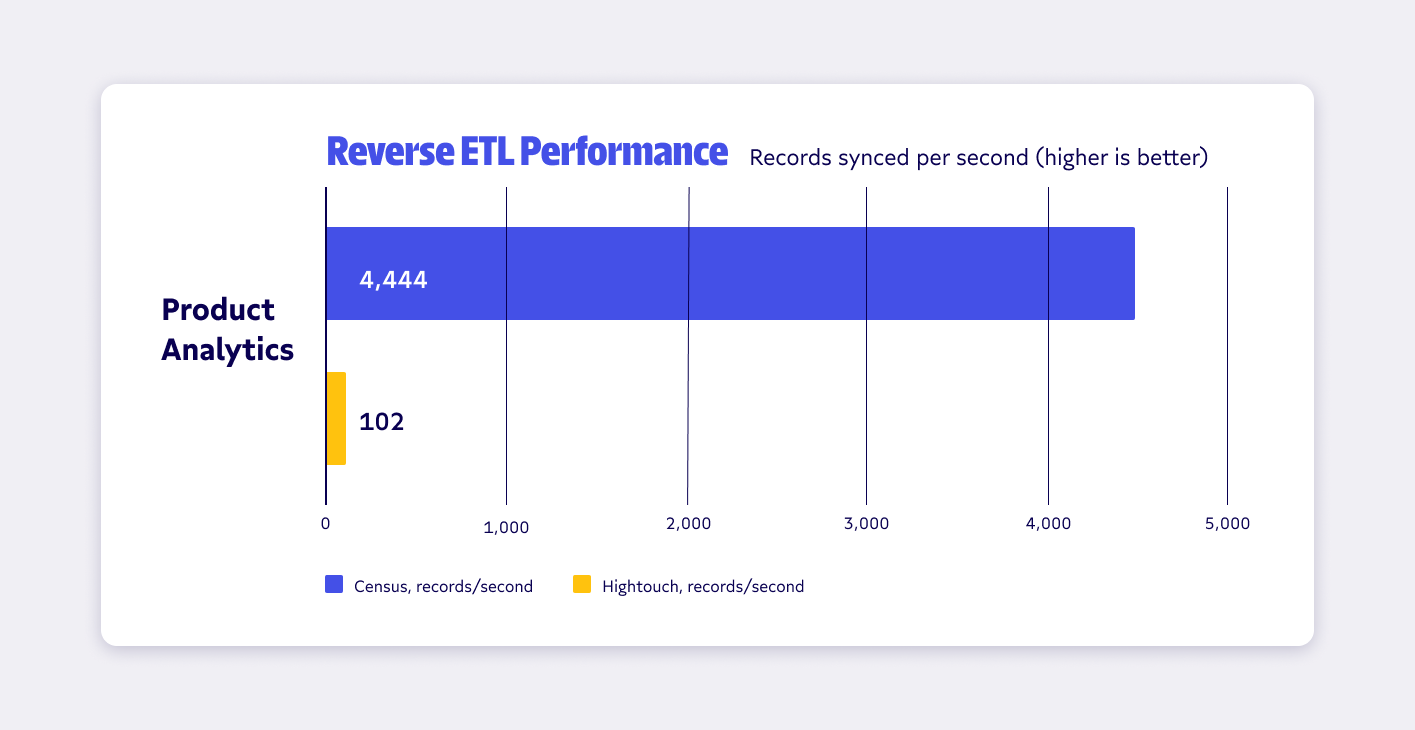
Let’s dive into the numbers and learn why reverse ETL performance matters and why you should include performance criteria when evaluating reverse ETL tools, how we’re structuring our benchmark tests, and the ground we’ll cover in future tests.
We also want to give you the opportunity to put our numbers to the test and arrive at your own conclusions, so we’ve also included instructions on how to replicate our benchmarks throughout.
Why speed matters for reverse ETL
As is the case with other integration platforms, source and destination systems generally constrain the performance of reverse ETL systems. Still, careful tuning and attention to maximizing the correct usage of those systems can make a massive difference in performance, as these results show.
Your company’s performance needs depend on your use cases, but we generally see three main reasons companies seek out high-performance reverse ETL:
- Real-time business use cases
- Large-scale event forwarding
- Maximization of agility and experimentation
Let’s take a quick look at why these matter for data-driven companies.
1. Real-time business use cases
Slow reverse ETL means stale operational data.
The latency of your reverse ETL system is directly proportional to its performance: The more records your system can move per second, the less time you’ll wait for data in your SaaS applications to match data in your warehouse. Inversely, slower loading means you’ll wait longer for business tools to reflect the accurate truth of your warehouse.
Whether you’re using data in your warehouse to assign leads in your CRM, prioritize tickets in your support platform, or deliver marketing emails to customers who reach critical steps in their journey, seconds and minutes can matter. This is especially important for establishing the trust your downstream data users have in your data. If they can’t rely on it and use it in the day-to-day decision-making, it doesn’t matter how many cutting-edge upstream tools you have in your stack.
2. Large-scale event forwarding
One of the most popular reverse ETL use cases is to use your data warehouse (along with a system like Snowplow) to collect, enrich, transform or filter events before delivering them to a downstream system (e.g. marketing systems like Braze or Customer.io or product analytics tools like Mixpanel or Amplitude).
Event data tends to have very high throughput and it’s not uncommon for systems to generate thousands of events per second (that’s hundreds of millions or even billions of events per month). If your reverse ETL tool can’t keep up with that load, backfilling isn’t an option–you’ll be “behind” the firehose as soon as you set up your first sync.
For event forwarding, performance isn’t a nice to have - it’s table-stakes.
3. Maximize agility and experimentation
After the initial first sync, a well-designed reverse ETL tool will only perform incremental syncs by using your warehouse to detect just the records that changed since the last sync and delivering those “diffs” to the destinations that need them.
However, incremental syncs may not always offer what you need from your data and you may want to backfill your entire dataset for a number of reasons:
- Completing initial setup
- Adding new “mappings” or destination attributes to a SaaS customer record
- Changing the definition of a lead score or other modeled attribute
To maximize the agility of your data or operations team, that team needs the freedom to make changes and quickly see their results, which means they need access to backfills that complete in minutes or hours, not days.
"Census means access to data is never a blocker for our revenue teams – if they want to run a growth experiment, the data is always available." - Julie Beynon, head of analytics at Clearbit
Deploying a slow reverse ETL system can leave your operational analytics initiatives dead on arrival. You need a system that can handle both your current load with ease, as well as one that has spare capacity to keep up with your company’s data volume as you scale and deploy more data pipelines. Don’t choose a system that can just barely keep up with your current workload.
Building benchmarks: How we tested reverse ETL performance
For our benchmarking, we’ve leveraged three different data warehouses and tested different business use cases with appropriately different record sizes.
In the coming weeks, we’ll share more benchmarks from testing our reverse ETL use cases and destinations, but here are the results from our first use case: Event syncs.

We’ve worked to make these benchmarks as simple and repeatable as possible and we encourage you to perform your own testing (and share your results!). To do so, you can grab the events data samples we used here (2.2 million events) and here (500k users).
In all cases, we used the self-service, free trial versions of Census and Hightouch with no special configuration to perform these syncs.
For Redshift, we configured an ra3.xlplus cluster with 16 nodes and for Snowflake we used a 2X-Large warehouse. In both cases, these are far over-provisioned given the size of the data, but we wanted to ensure that the source warehouse was not an artificial bottleneck. We used synthetic datasets with a mix of data types that were realistic for the given destinations.
The destination systems (in this case Mixpanel) were the same for both tools (same rate limits and other configuration). Hightouch rounds its displayed sync times to the nearest minute or hour, so we used those numbers as displayed in the UI. The workloads did not include any error or skipped records, and all syncs were completed successfully with 100% of records loaded in both systems.

Gearing up for the long-haul: What’s next in our benchmark series
While we’re excited to share these preliminary findings with our community, there’s a lot more benchmarking and deep-diving to be done into why Census is so much faster, as well as how we stack up against other tools for additional use cases.
Over the coming weeks, we’ll share use-case-based benchmark reports like this one focused on areas such as CRMs and marketing tools, additional destinations such as Salesforce, Hubspot, Marketo, and Customer.io; and include other reverse ETL tools in the space so you can get a complete picture of your options. We’ll also update numbers as our testing evolves, and take a deep dive into some of the secrets behind the speed of our reverse ETL tool.
In the name of transparency, we’ll detail how we’re measuring our performance at each step and offer ways that you can repeat these tests yourself.
Through this benchmarking work, we’ve uncovered opportunities to make Census perform even better for high-scale workloads, which means the bar for “good reverse ETL” is getting higher every day. We’ll continue to share updates with new benchmarks as we push the limits of reverse ETL speed.
As we share our findings, we encourage you to let us know which systems and use cases you’d like to see benchmarked next.
Finally, we’ve always aimed to build the most performant and reliable Reverse ETL platform to power business-critical operational workflows, and we wholeheartedly support competition in the category that continues to push the limits for our customers. As such, we invite Hightouch and any other reverse ETL providers to share updated benchmarks so we can collectively push this category of data tooling to new heights.
In the meantime, if you have any questions or suggestions on how we can make this and future benchmarks useful to you, feel free to reach out and say hi at hello@getcensus.com.