

































Reverse ETL induced demand for data
When we built our original data pipelines (aka. reverse ETL), we created a new gold standard for turning analytics & insights into action. With our hub & spoke model on top of the cloud data warehouse, data teams could deploy models into any application, allowing ops teams to power better sales processes, more personalized marketing engagement, faster finance workflows, and much more. Unlocking the data sitting unused within companies remains a huge problem & opportunity today.
Demand leads to new bottlenecks
With reverse ETL, we redefined the scope of a data team – beyond dashboards and towards powering critical business workflow by syncing into 200+ applications (something we dubbed "operational analytics"). This means they are on the hook for delivering more data at high quality and low latency. Success might mean drowning in tickets to build new columns! Our product offering has grown to help data teams keep up with the demand.
Self-service
To help data teams keep up with this growth, we've added self-serve tools for business users to build new audiences. By bringing these consumers into the platform, everyone moves faster without sacrificing the data team's ability to monitor syncs and control for quality.
We added these capabilities on top of our warehouse-native architecture, which turned our platform into a CDP "toolkit" that helps data & marketing teams work together better than before (today, folks refer to this pattern as a "composable CDP").
Latency
Consumers expect trusted/modeled data as fast as possible (e.g. is this new signup part of a paying organization?), which is difficult when you have to coordinate between a data source, a transformation engine, and a system of action. If these teams can't access data from the central hub as quickly as they need to, they fall back on peripheral tools, which creates silos. With our recent launch of real-time syncing directly from data warehouses, we're starting to see the lines between trust and latency disappear. Latency was one of the last major barriers to adopting central data models.
What bottlenecks remain?
Behind pipelines lie the models
With businesses activating more data more quickly than ever, data teams must constantly source new data and deliver ever-changing useful data models.
Census simplified this process by integrating with tools like Python, dbt, and SQL, which means one less step between making changes and deploying the results.
But still, too much falls through the cracks. The #1 thing I hear from folks I meet is that they barely use the data they have! When ops teams find themselves waiting in ticketing queues or experiencing delays in getting the models they need, they fall back on their own tools to transform data (eg. Salesforce or spreadsheets). This duplicates modeling efforts, perpetuates silos, and makes it impossible to centralize and govern models.
Mind the (data) gap
The data stack is replete with transformation tools but collaboration between technical & non-technical teams is crucial if we're to expand the envelope of the shared data platform.
Our goal for Census is to be a universal data platform. One in which data is accessible to everyone and in which business operations depend on and help maintain. There's a slew of capabilities to add but the most important is creating a shared environment where users from every team can satisfy their data needs under the watchful eye of the data team. A recent example is our launch of Computed Columns on Datasets, which allows ops teams to modify models in the same system as the data team, but with a UI they love that doesn't require code.
For data teams, this means a single place to source, manage and deploy models across the data lake. It means data models remain governable and avoids duplicated or siloed data.
Our platform further closes the gap by guaranteeing that models are usable by all the apps in the environment, by reducing latency and operating in real-time, by reducing duplication, and providing a foundation of observability across every teammate participating in modeling or deployment work.
Our ever-present mission
We started Census to give every app and person access to data they trust to automate the business. Personally, I've always been obsessed with the idea of end-user programming – to give everyone in a company the power to "program" the business on top of a consistent view of data.
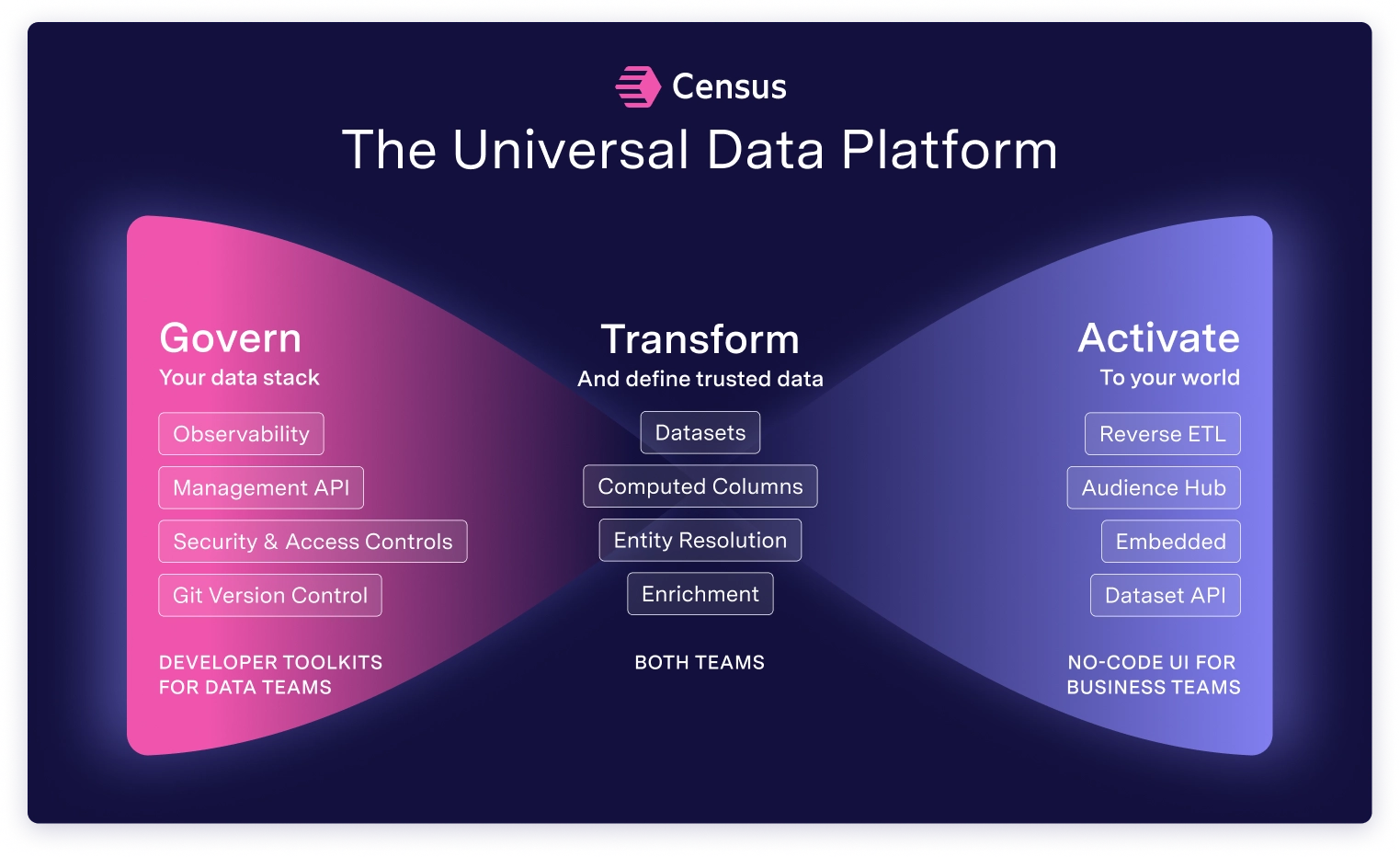
There are 3 pillars to delivering a universal platform that people can use to build any workflow.
- Transform. Business workflows can't rest on random data tables. The platform must assist data & operations teams in building useful semantic models that span all their data sources. These models should be versioned like code.
- Govern. The platform must enforce rules like PII across any application, even across organizations (consumer expectations & regulations are increasing). It must provide deep observability to trace every historical access. It should monitor usage to reduce duplication and bad data.
- Activate. The platform must reach any system as fast as possible. It must have a rich API for third parties and a world-class connector library to modify end-systems. It should provide easy ways to build workflows that can be monitored.
Our work is never done
It’s an exciting time for the data ecosystem and for tools like ours that make data accessible. The data lake continues to get better with the adoption of Iceberg, which will lead to less superfluous data movement and even more choice for compute engines. Our job at Census in this world remains turning data into something useful & usable (aka. “semantic”) that can drive operations.
We extended the envelope of our data platform to include external organizations by extending the governance and user experience. With Census Embedded, we’ve paved the way for sharing data across organizations without sacrificing trust or speed.
And the world of CDPs is evolving with more folks embracing the data lake! There will always be new tools for engaging with customers and building ever more complex marketing cross-channel campaigns. Our goal remains to help these tools flourish with more trustworthy semantic models that are ready-to-use. With the quantity of data and sources continually increasing, our focus is on helping teams build great unified models so that downstream tools can provide engagement and analysis.
Up until now the primary consumers of data were people in SaaS applications. We’ve built a semantic layer on top of the data sitting in warehouses that serve these operational goals (e.g. how users relate to workspaces and events so that you can build audiences using these relationships). Now we can glimpse a new world of data consumers in the guise of agents and copilots. It’s nascent but an exciting addition to the roster of things that need data they can trust. We’re looking forward to building something ever-more unified and universal to serve these agents!