

































Last week we hosted a hands-on SQL workshop with a master of the craft, Ergest Xheblati. He’s spent the last 15 years refining his SQL skills and captured those skills in his book, Minimum Viable SQL Patterns. In this workshop, Ergest explains and demonstrates various principles from his book, such as:
🎯 Query decomposition patterns - Solve complex queries by systematically decomposing them into smaller ones
🎯 Query maintainability patterns - DRY principle (don't repeat yourself)
🎯 Query performance patterns - Make your queries faster (and cheaper)
Toward the end of the workshop, Ergest answered over a dozen questions from SQL professionals all over the world. Here’s a summary of all the major topics covered. 👇
Query decomposition patterns
As SQL practitioners, we often find ourselves writing 50+ line queries to answer business questions. Sure, these queries get the answers we’re looking for, but without discipline, they can be annoyingly difficult to read. And if you, the creator, can barely follow along with the query, it’s unlikely that your data team will be able to either.
The solution? Common Table Expressions (CTEs).
When you use CTEs correctly, you can break down a large query into smaller, independent pieces (AKA decompose them), allowing you to easily read your query as a direct acyclic graph (DAG). Ergest used a real-life example in his video with several subqueries converted to CTEs, but here’s a simple side-by-side comparison from Alisa Aylward.
CTE:
WITH avg_pet_count_over_time AS
(
SELECT
cat_id,
MAX(timestamp)::DATE AS max_pet_date,
MIN(timestamp)::DATE AS min_pet_date
FROM cat_pet_fact
GROUP BY 1
)
SELECT
cat_name,
t1.max_pet_date,
t2.min_pet_date
FROM cat_dim
LEFT JOIN avg_pet_count_over_time as t1
ON cat_dim.cat_id = t1.cat_id
LEFT JOIN avg_pet_count_over_time as t2
ON cat_dim.cat_id = t2.cat_id;Subquery:
SELECT
cat_name,
t1.max_pet_date,
t2.min_pet_date
FROM cat_dim
LEFT JOIN
(SELECT
cat_id,
MAX(timestamp)::DATE AS max_pet_date,
MIN(timestamp)::DATE AS min_pet_date
FROM cat_pet_fact
GROUP BY 1) AS t1
ON cat_dim.cat_id = t1.cat_id
LEFT JOIN
(SELECT
cat_id,
MAX(timestamp)::DATE AS max_pet_date,
MIN(timestamp)::DATE AS min_pet_date
FROM cat_pet_fact
GROUP BY 1) as t2
ON cat_dim.cat_id = t2.cat_id;Notice how much easier the query with CTEs is to read?
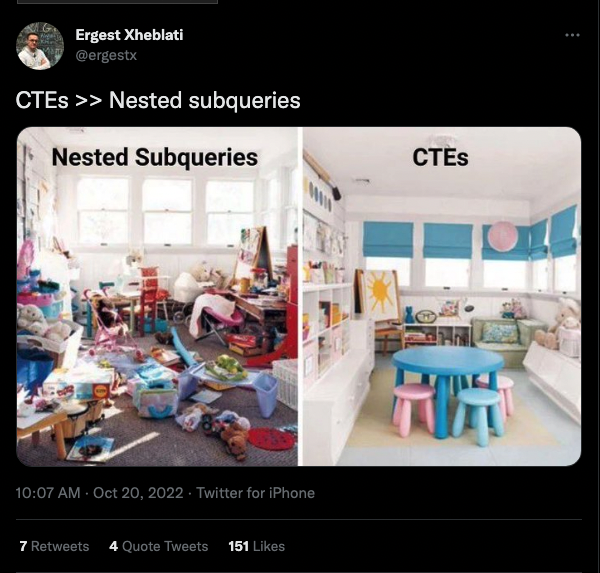
In fact, switching from nested subqueries to CTEs is similar to switching from a messy bedroom to an organized one, Ergest highlighted in a recent tweet. Like a clean room, a CTE query is more manageable – plus, it’s much easier to find whatever you’re looking for if it’s always in the right place.
|
Query Maintainability Patterns
After learning how to make queries more readable, Ergest explained how CTEs make queries more maintainable. Whenever you need to debug a query, you can investigate the individual DAG-like CTEs from beginning to end until you find the issue. This can save you hours in a day and allow you to get started on your never-ending to-do list. 📝
Ergest also discussed the don’t-repeat-yourself (DRY) principle. Here’s the TL;DR: If you find yourself copying and pasting code frequently, you’re better off creating views for your CTEs, which reduces the lines of code per query.
Query performance patterns
Next, Ergest described how to make queries more performant and cost-effective, something he calls a “query performance pattern.” He shared a few rules to follow 👇
- Avoid using sort operations until the final
SELECTstatement. Sort operations (ex.ORDER BY) aren’t necessary until your query is in its final format. - Avoid joining data until you’ve reduced the data as much as possible. Before you join data, filter out all unnecessary columns and rows.
- Avoid using functions in the
WHEREclauses.WHEREClauses are capable of handling complex functions, but they reduce performance. It’s negligible when dealing with small queries, but if you’re dealing with millions or rows, it can get costly, so make the where clauses as simple as possible.
Following these rules will reduce query run times and save your organization money. 💰 Even if you’re dealing with small amounts of data now, practicing query performance patterns will make you a SQL expert in the long term.
Audience Q&A
After chatting about the three principles above, Ergest answered dozens of questions from SQL practitioners around the world. These are three (of the many) that I found valuable:
🤔 Why should you wait until the end of a query to join data? Is it for performance or organization?
- Organization. You want to limit the scope of CTEs to simple aggregations because it makes it much easier to change in the future (query maintainability pattern). Additionally, if you are joining data in CTEs you might as well create a new table of the joined table rather than constantly writing a
joinstatement.
🤔 What are your suggestions for where and how to comment in SQL?
- I believe in self-documenting code. If your code is simple (following the query decomposition pattern), you don’t need to write comments. If you’ve taken the time to properly name your tables and CTEs, they should explain themselves.
🤔 What is the performance/readability difference between using CTE and temp tables?
- Temp tables and CTEs are equivalent in terms of performance. However, I believe CTEs are easier to read (Query decomposition patterns).
This blog is a brief summary of everything Ergest taught in the workshop. If you’d like to level up your SQL skills and learn more, check out the full workshop here.
✨ Then head on over to join the Operational Analytics Club so you can discuss what you learned!